A Classifier That Reads No Articles Still Hits F1 = 1.000 on This Fake News Benchmark
On a 44,898-article Kaggle fake news dataset, a TF-IDF classifier using only the subject and date fields reaches F1 = 1.000. The text-based headline model lands at 0.9980. That gap is the real finding.
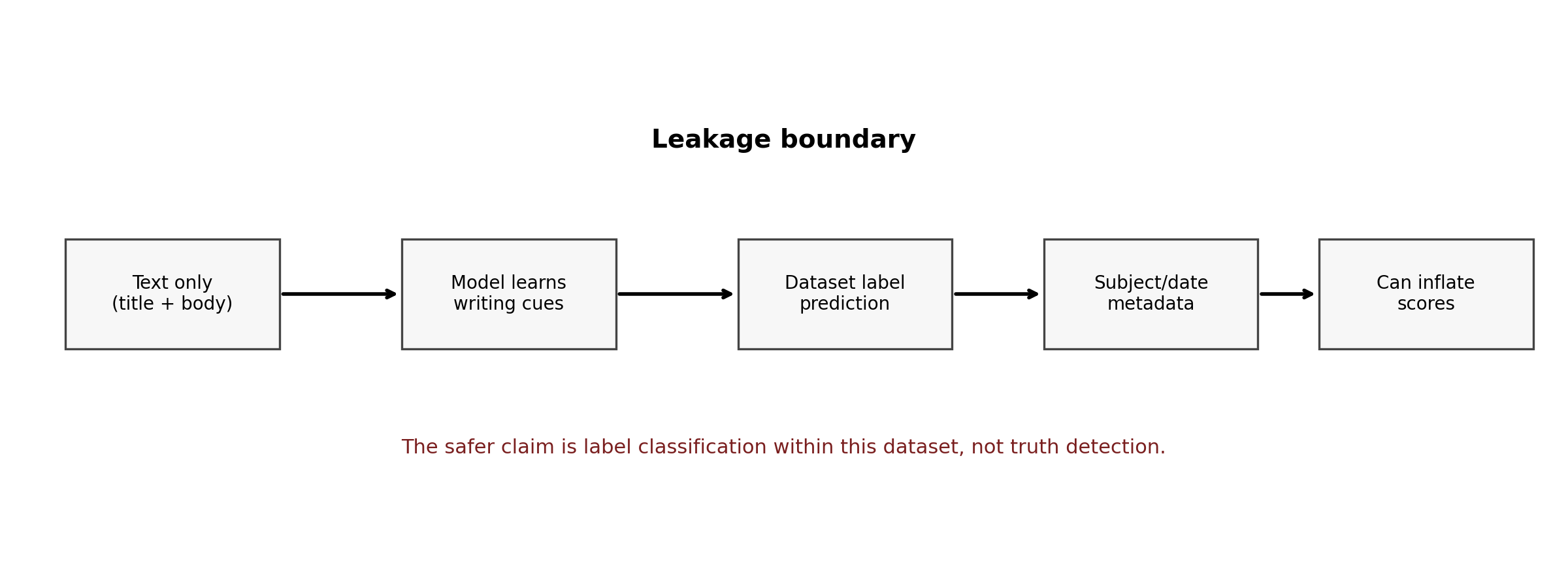
A linear classifier trained on the Bisaillon Fake and Real News Kaggle corpus reaches F1 = 0.9980 on a stratified 1,993-row holdout. That number looks good. The same classifier, with the article text stripped out and only the subject and date fields retained, reaches F1 = 1.0000 on the same holdout. That number is the real finding.
The rest of this post is the argument that a benchmark which can be solved without reading a single article is not, in any useful sense, a fake-news-detection benchmark. It is a source-identification benchmark wearing a fake-news label. Whether that distinction matters depends on what you want to do with the model.
The dataset
The corpus is Clément Bisaillon’s Fake and Real News Dataset, distributed on Kaggle as two CSV files with labels assigned by file of origin (Bisaillon, 2020). Fake.csv carries 23,481 articles labeled fake; True.csv carries 21,417 articles labeled real. Combined rows: 44,898. Class share: 52.3 percent fake against 47.7 percent real.
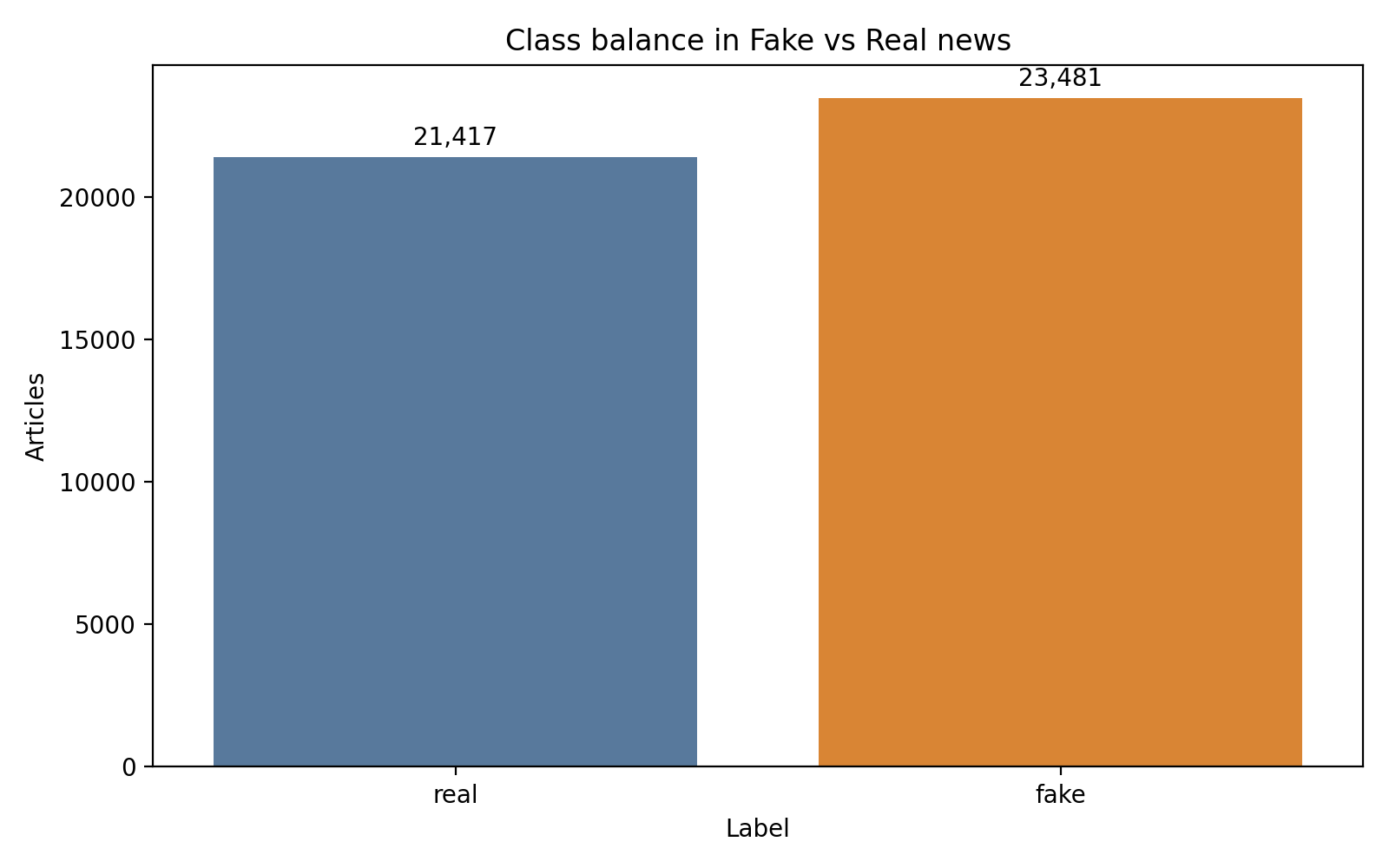
Class share is close enough to even that accuracy and F1 track together. The majority-class baseline floors at F1 = 0.6682, which is the number any real model has to clear.
Three data-quality findings condition the rest of the work. The corpus contains 211 exact duplicates. A further 631 rows have empty or near-empty body text. The date field only parses to a datetime for 33,285 of the 44,898 rows, a 74.1 percent parse rate that is too unreliable to engineer features from. Where date parses, the range runs from May 2015 to December 2017, heavily weighted toward 2017.
The four retained fields are title, text, subject, and date. Each has distinct properties. title and text are the fields you would expect a text classifier to use. subject and date are the fields you would expect to be ignored in a task called “fake news detection.” That expectation is the trap.
The length signal shows up before any model runs
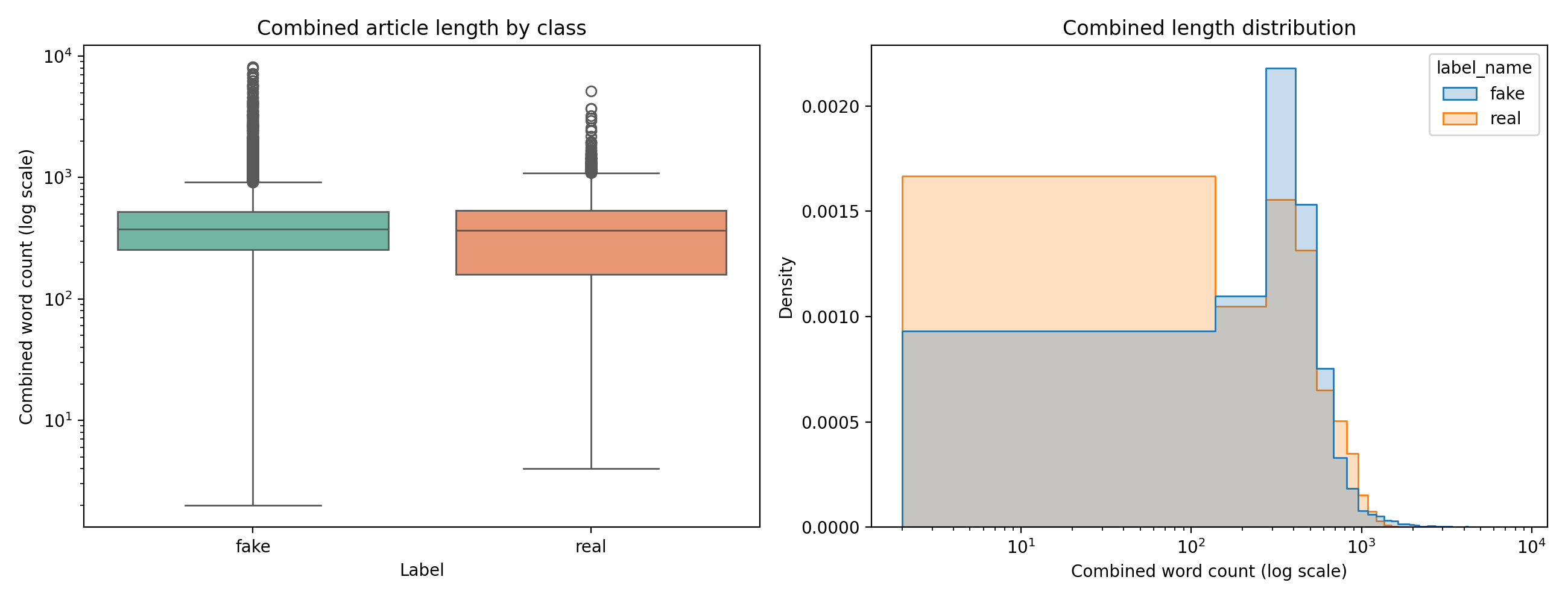
Real articles run longer: median body 362 words against a shorter fake median, with less variance in structure. Length is a classification signal by itself.
Median title length across the corpus is 11 words. Median body length is 362 words. Median combined length is 375. Real articles run longer on average and show more structural consistency than fake articles. That gap is already a feature a TF-IDF model can exploit before it sees a single informative word, because TF-IDF is not length-invariant and longer documents accumulate more discriminative tokens.
None of that is the main problem. It is the warm-up problem.
The subject field is a copy of the label
Here is the table that does all the work in this project.
| Subject | Row count | Side |
|---|---|---|
| politicsNews | 11,272 | real |
| worldnews | 10,145 | real |
| News | 9,050 | fake |
| politics | 6,841 | fake |
| left-news | 4,459 | fake |
| Government News | 1,570 | fake |
| US_News | 783 | fake |
| Middle-east | 778 | fake |
The top eight categories do not cross the class boundary. politicsNews and worldnews live entirely on the real side. News, politics, left-news, and several smaller categories live entirely on the fake side. The visual:
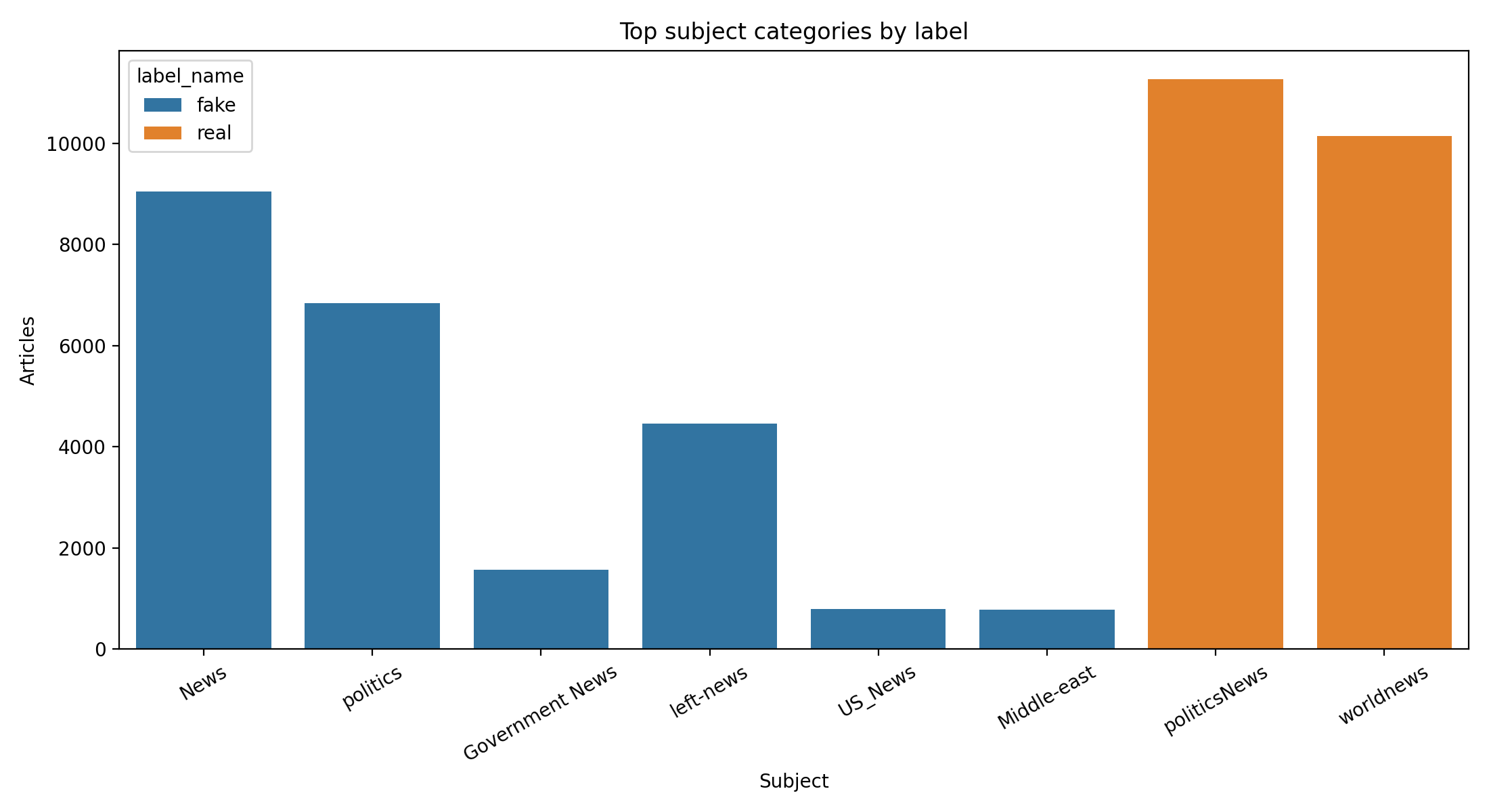
Subjects do not overlap across classes. The field is a near-copy of the label under a different column name. A reader who knew nothing about the labeling protocol could recover the class assignment from the subject alone with very high accuracy.
That is what corpus-structural leakage looks like when it is staring at you. The subject field exists in the dataset for descriptive purposes; each file (Fake.csv and True.csv) appears to draw from a different editorial taxonomy, so when the two files are concatenated and the label is derived from the source file, the subject field becomes a second column that carries the same information as the target.
A classifier that uses the subject field as a feature is not learning to detect fake news. It is learning that articles with subject = politicsNews come from True.csv and articles with subject = News come from Fake.csv.
The diagnostic ladder
To make that claim concretely rather than as hand-waving, I ran five model configurations on the same stratified 1,993-row holdout at random seed 42. All text configurations used TF-IDF with unigrams and bigrams and scikit-learn’s SGDClassifier.
| Model | Features | Accuracy | F1 | ROC-AUC | PR-AUC |
|---|---|---|---|---|---|
| Majority prior | label prior | 0.5018 | 0.6682 | 0.5000 | 0.5018 |
title_only_sgd | title | 0.9313 | 0.9312 | 0.9817 | 0.9831 |
title_text_sgd | title + body | 0.9980 | 0.9980 | 0.9999 | 0.9999 |
title_text_subject_sgd | title + body + subject | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
metadata_only_sgd | subject + date only | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
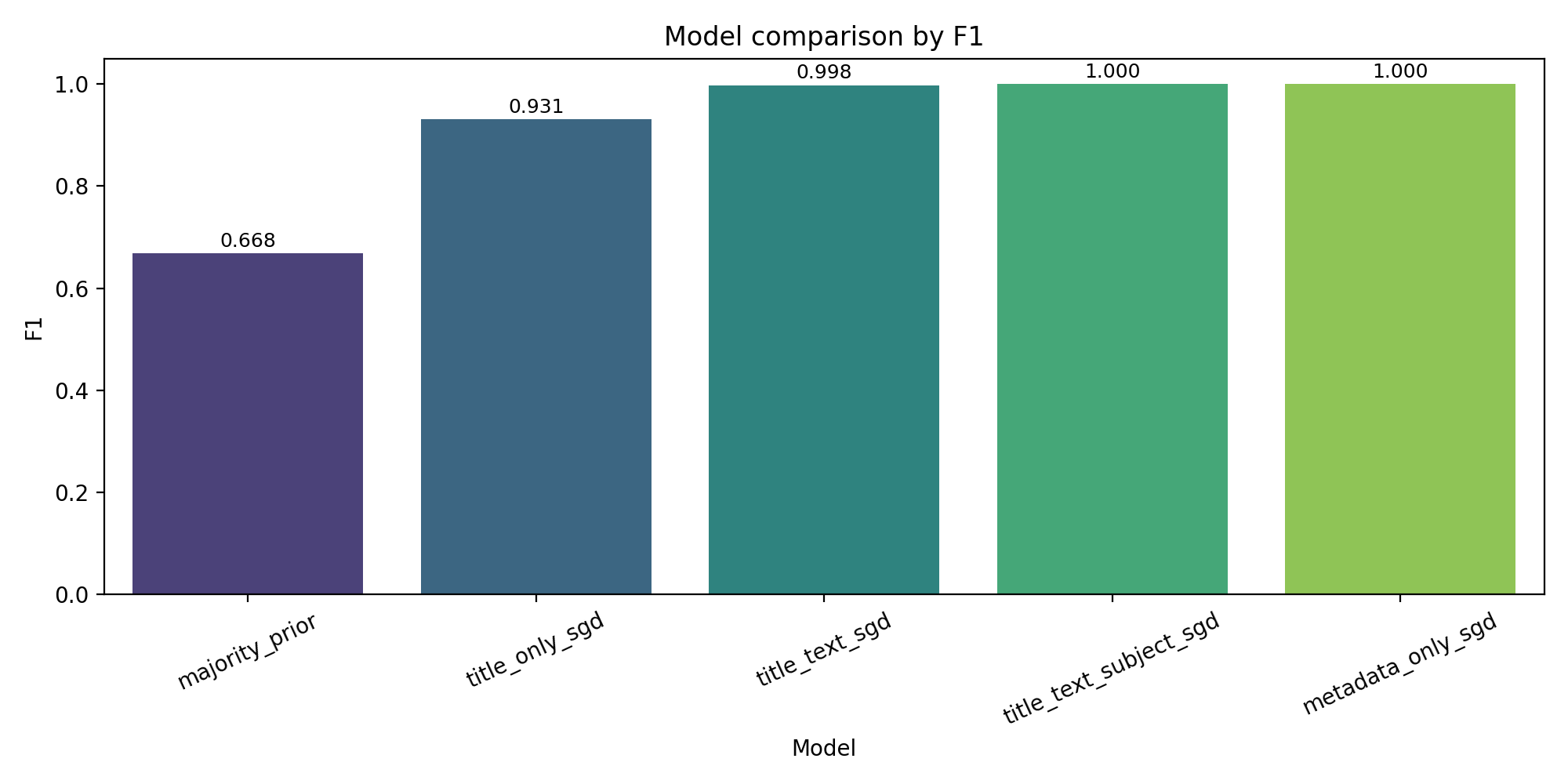
The text-only title plus body variant is the strongest defensible deployment candidate. The two runs that include the subject field both reach 1.000 on every metric. The metadata-only run is the centerpiece: it never reads an article.
Reading the ladder in order: the majority baseline sits at accuracy 0.5018 and F1 0.6682. Title-only TF-IDF jumps to F1 0.9312 using only headlines. Adding the article body pushes F1 to 0.9980 and ranking metrics to 0.9999 on both ROC-AUC and PR-AUC.
Then the bottom two rows break the ladder. Adding subject on top of the already-strong text model pushes every metric to 1.000. Stripping the text entirely and using only subject and date also reaches 1.000 on every metric. The second of those is the diagnostic: a model that never reads a word of the article text still achieves a perfect score because the subject field is, functionally, the label in disguise.
The confusion matrix for the text-only model gives a sense of what the near-ceiling failure mode looks like.
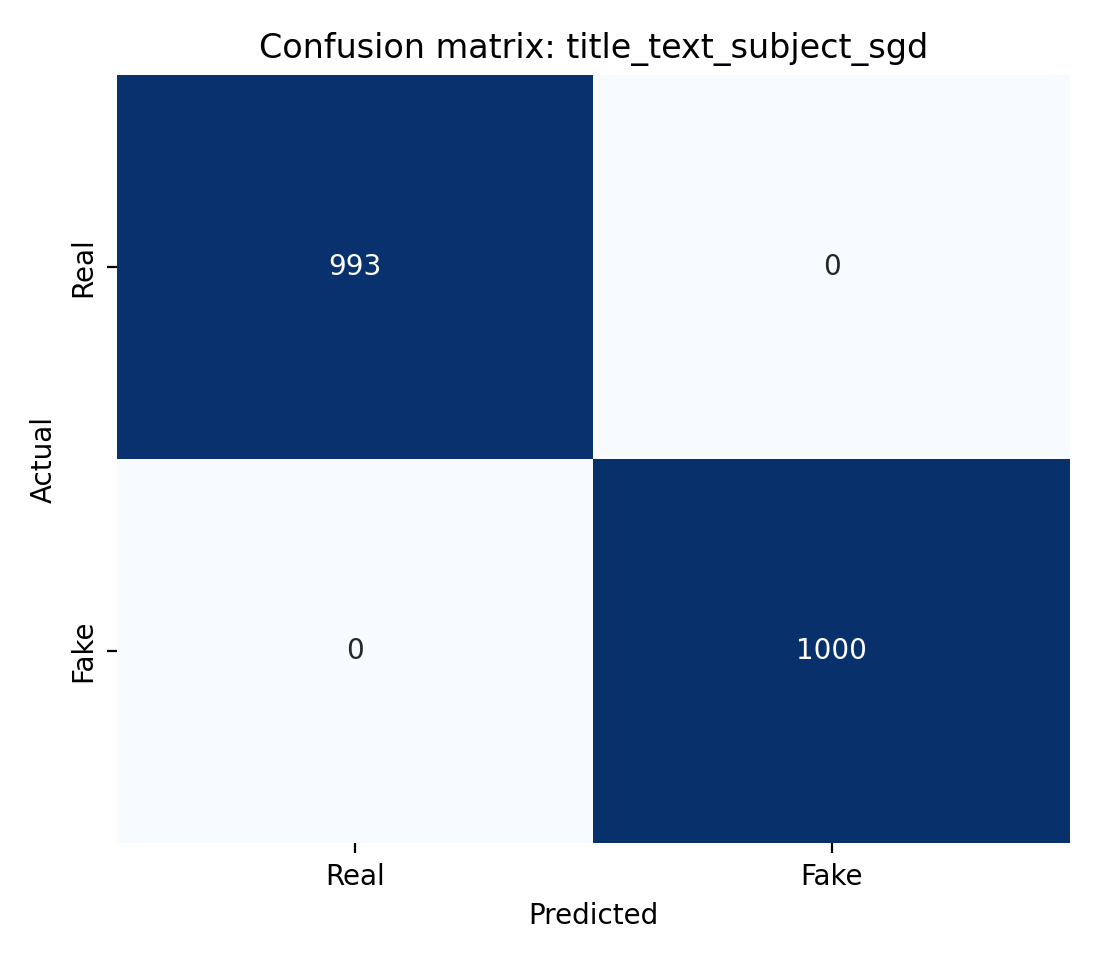
Near-ceiling performance. Two misclassifications on the 1,993-row holdout for the text-only variant. At this sample size, the confidence interval around that number is wider than the error itself.
The precision-recall curve tells the same story in a different shape.
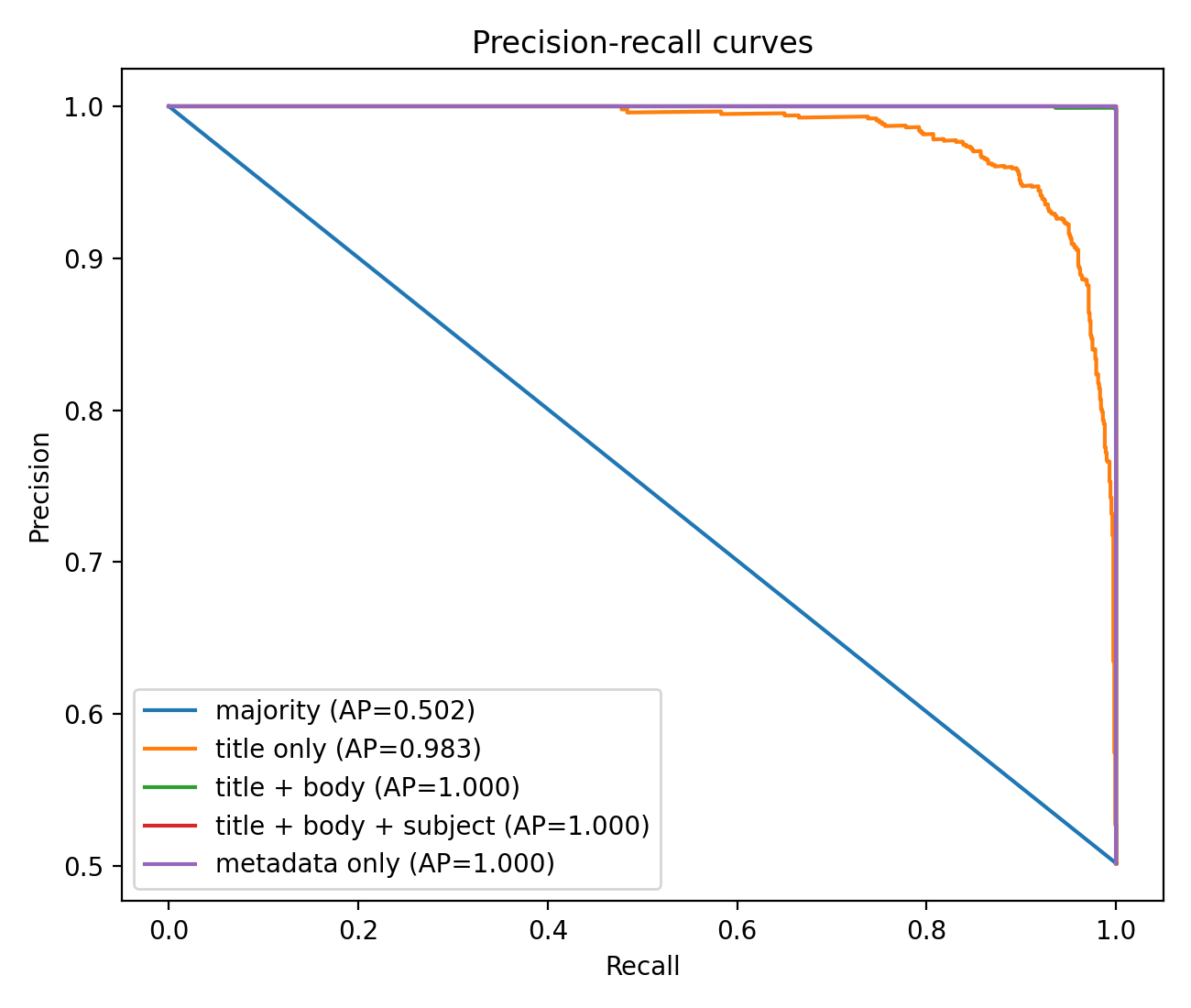
Precision stays at or near 1.0 across nearly the full recall range, which is the geometric restatement of the F1 = 0.9980 result. The curve looks suspiciously perfect, and that is the warning.
What the coefficients are actually picking up
Coefficient inspection on the text-only model clarifies what the classifier has learned. The tokens with the largest absolute weights are not content tokens. They are source signatures.
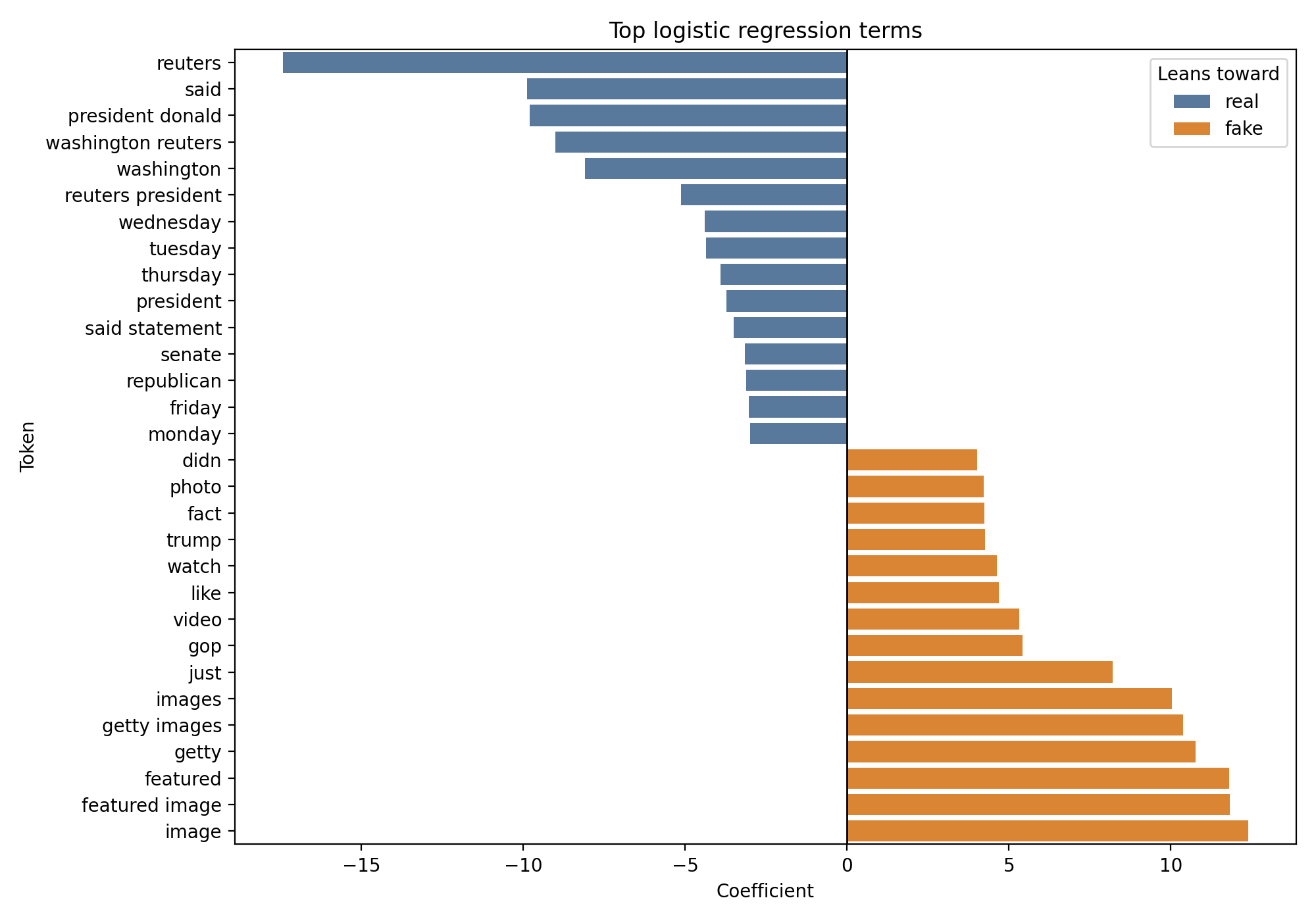
Top-weighted terms on the real side include reuters, said, and washington reuters. Top-weighted terms on the fake side include image, getty, and headline fragments common to one publication family.
On the real side, the heaviest positive coefficient is on the token reuters, with a weight around minus 17.42. Other real-weighted terms include said at minus 9.89 and the bigram washington reuters at the same scale. These are wire-service attribution patterns. The model has learned that articles with Reuters boilerplate come from True.csv.
On the fake side, the heaviest positive coefficient is on the token image, with a weight around 12.38. Other fake-weighted terms include getty at 10.76 and a family of headline-style phrasing patterns specific to the publication pool the fake file was drawn from.
None of those features are truth signals. They are identification signals for the source pool.
What this actually means
There are two honest readings of this result, and both matter.
The narrow reading is that the title_text_sgd configuration at F1 = 0.9980 is a high-quality benchmark result. Given how publishing platforms actually look, using the text-only model as a triage aid that orders a 1,993-row review queue for a human editor is a defensible deployment choice, as long as the human in the loop understands that the model is recognizing the source pool it was trained on and is likely to fail on articles from sources it has never seen.
The wider reading is that the benchmark is not measuring what its name implies. A classifier that reaches 1.000 without reading an article is not detecting fake news. It is detecting the source of the article, which happens to correlate with the label because the label is derived from the source. Any paper or model card that reports accuracy on this corpus without acknowledging the subject-field leakage is reporting a number that doesn’t describe what the reader thinks it describes.
The broader literature on fake-news detection has been flagging exactly this class of problem for almost a decade. Shu and colleagues (2017) survey the field and argue that corpus-fitted classifiers often learn shortcuts that do not survive out-of-distribution testing. Rashkin and colleagues (2017) analyze linguistic markers of deception and find that the most deceptive writing is rarely the most stylistically extreme, which means simple surface features can make a corpus-fitted model look successful without teaching it anything about truth. Pérez-Rosas and colleagues (2018) show the same n-gram models hitting high within-domain accuracy while generalizing poorly across domains. Zhou and Zafarani (2020) synthesize the broader picture: benchmark numbers in this field routinely overstate deployment-ready capability.
What this project adds is not a new observation. It is a specific, reproducible instance of the pattern, on a widely downloaded Kaggle corpus that is still being cited as a legitimate fake-news benchmark.
Reproducibility note
The full pipeline runs end-to-end from the raw Kaggle CSV through deduplication, balanced sampling, stratified splitting, TF-IDF vectorization, five model fits, coefficient inspection, and every figure in this post. Source code, the notebook, and the figure outputs live in the public repository at github.com/ndjstn/fake-news-detection. The dataset is Bisaillon’s clmentbisaillon/fake-and-real-news-dataset on Kaggle and must be downloaded separately.