When the Description Field Does the Work: A Netflix Content Recommender
TF-IDF over Netflix title descriptions and genre tags produces top-10 lists that read like a curator's suggestions. The failure mode is not what I expected.
I built a TF-IDF recommender over 8,807 Netflix titles — the one-sentence description field plus the genre tags — and the top-10 lists it produces read like something an actual curator would suggest. Stranger Things returns Nightflyers, Helix, and Chilling Adventures of Sabrina in the top five. Squid Game returns Kakegurui and Til Death Do Us Part, both Korean and international thrillers. Black Mirror returns a cluster of British TV dramas.
That last one is the interesting failure. The signal in Black Mirror’s vector is dominated by its “British TV Shows” and “International TV Shows” tags, so the neighborhood fills with British dramas that have nothing to do with the sci-fi-horror vibe. The model isn’t wrong — the British-show tag does describe Black Mirror — but it prioritises the wrong similarity dimension.
The data
8,807 rows from Shivam Bansal’s Netflix titles CSV on Kaggle. Each row carries the usual: title, type (Movie or TV Show), director, cast, country, release year, rating, duration, genre tags (listed_in), a one-sentence description. 6,131 of the rows are movies and 2,676 are TV shows.
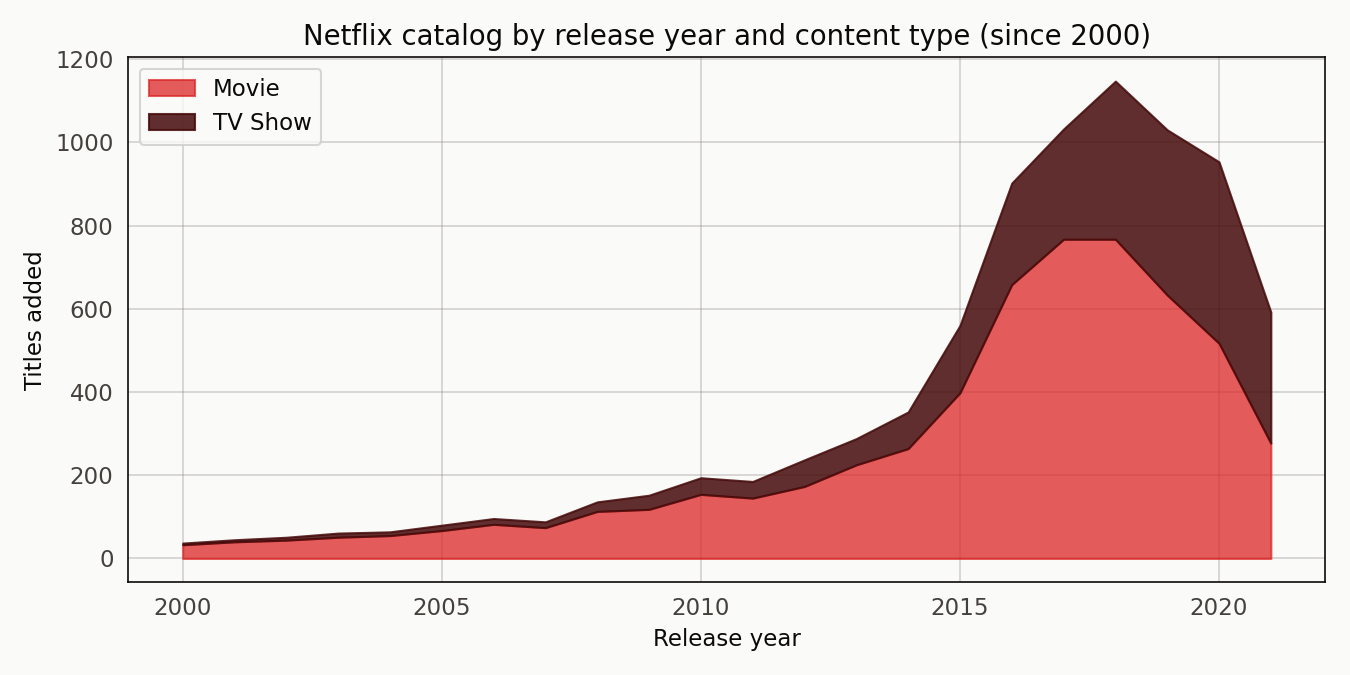
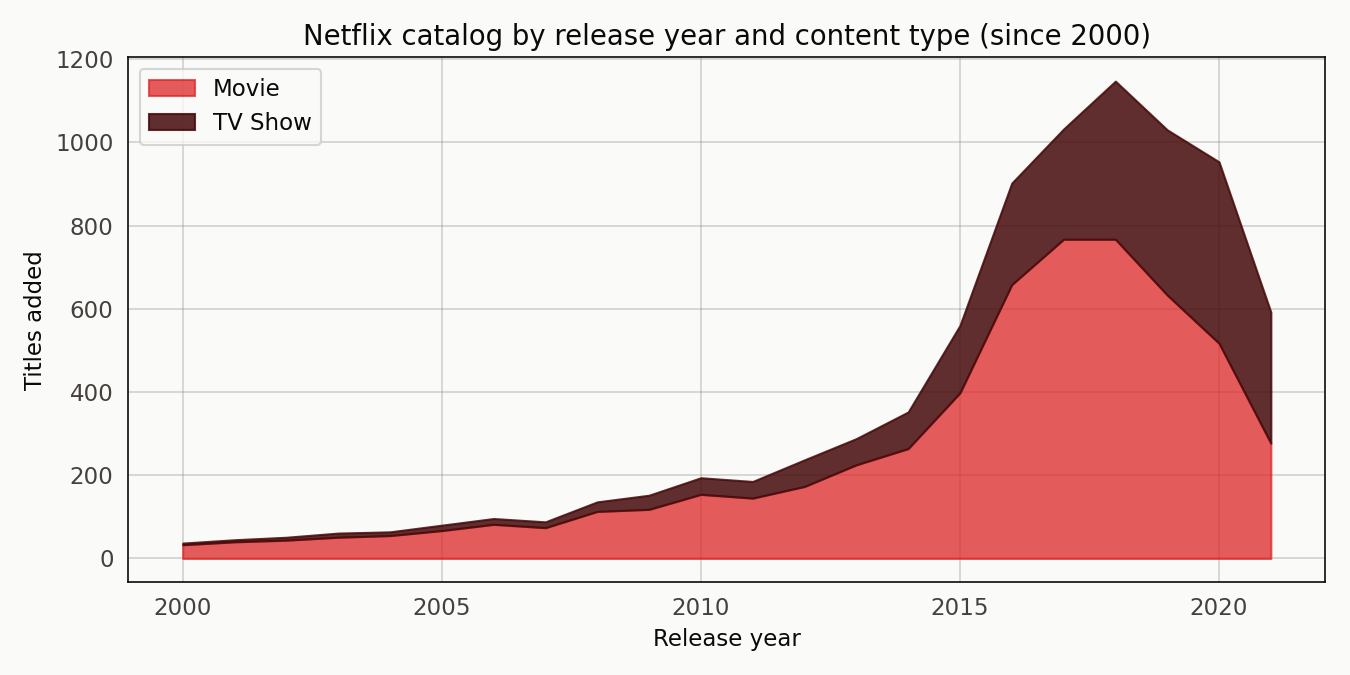
The catalog grows through the 2000s and 2010s with a visible step-up around 2016 when Netflix’s original-content slate scaled. Movies dominate until the TV Show band starts pulling away in the mid-2010s.
The top genre tags look demographic-ish: International Movies at the top with 2,752 titles, Dramas at 2,427, Comedies at 1,674.
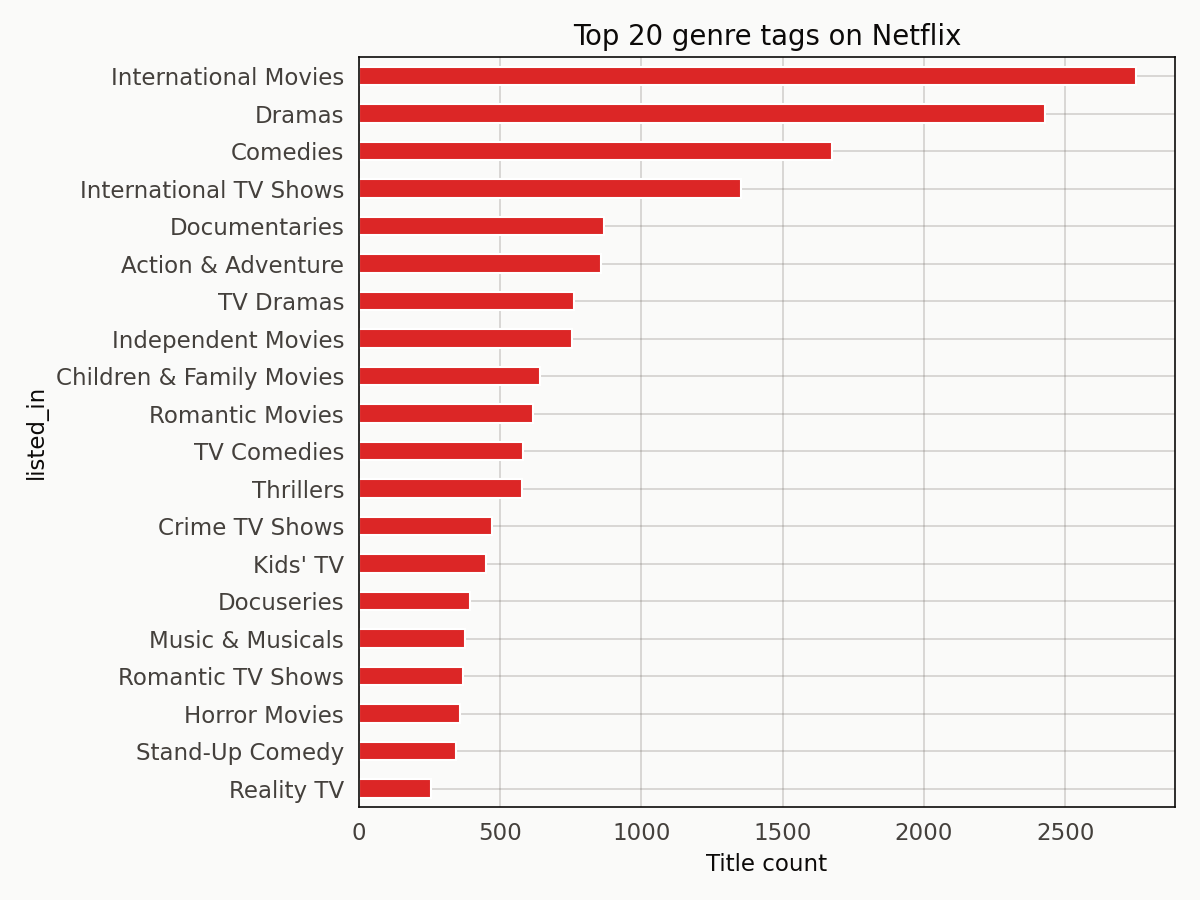
Some tags function like audience labels (Kids’ TV, Children & Family Movies); others like content descriptors (Crime TV Shows, Horror Movies). The recommender treats them all identically, which turns out to be the thing to fix.
The recommender
TfidfVectorizer with English stopwords, 1-2 n-grams, minimum document frequency of 3, capped at 20,000 features. Genre tags get repeated once in the token stream for a slight weight boost. The vectoriser L2-normalises by default, so the dot product is the cosine similarity.
Given a query row, the recommender takes the dot product of that row’s vector against every other row’s vector and returns the top-k. That’s the whole thing.
The surprise: it already respects the type boundary
I expected the naive TF-IDF recommender to leak across Movie/TV Show types the way the Spotify audio-similarity recommender leaks across genres. That’s the textbook failure mode.
Netflix doesn’t leak. Across 500 random queries, 99.3 percent of the top-10 share the query’s type. Adding a type penalty of 0.15 pushes the rate to 99.9 percent, but the jump is in the noise. The recommender respects the type boundary almost automatically.
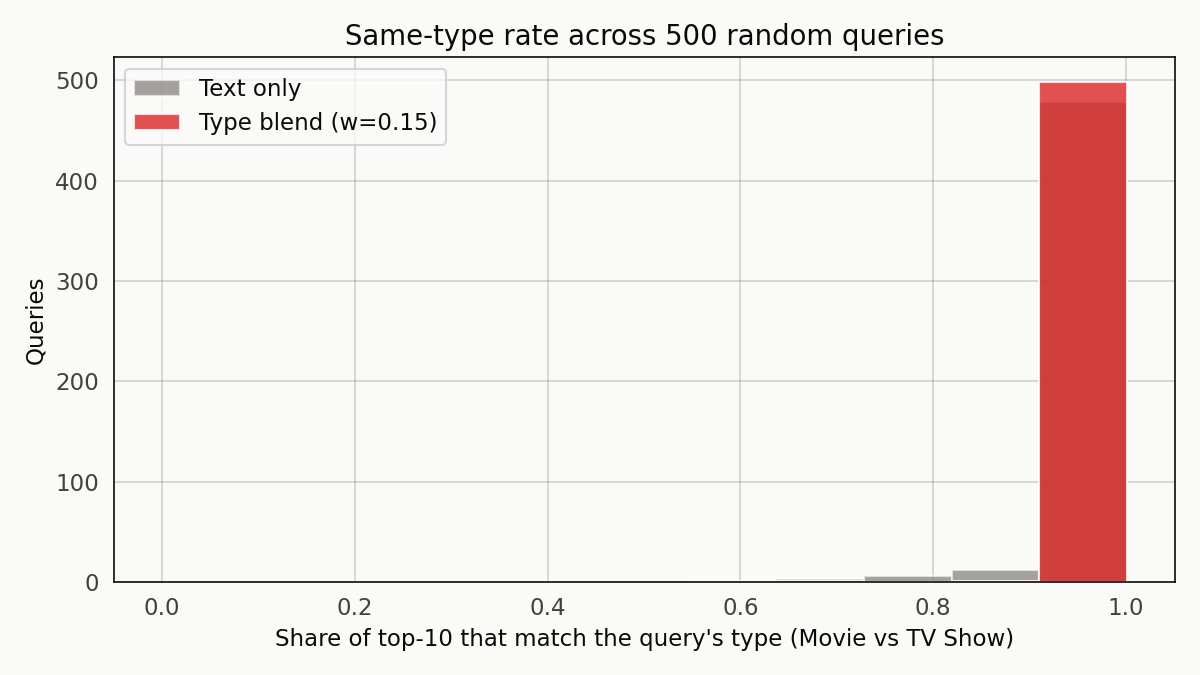
Anti-climactic figure. Both distributions pile up at the right edge. The type boundary isn’t the problem.
The reason is structural. Movie descriptions and Show descriptions carry different vocabulary. Movies get language like “stranded”, “a thriller”, “a romantic comedy”; Shows get language like “a series follows”, “each episode”, “across multiple seasons”. TF-IDF picks up on those verbal markers without being told to. The genre tags themselves include TV Shows or Movies substrings that reinforce the signal.
The real failure: genre-tag shadowing
The problem shows up when a title’s tag list includes a dominant tag. Black Mirror’s tags include “British TV Shows” and “International TV Shows”. Both of those tags are moderately common — frequent enough to appear across hundreds of titles — so when the recommender scores neighbors, it leans on tag overlap rather than description similarity.
The result is that Black Mirror’s neighborhood fills with British dramas that share nothing else with it. Leila, Downton Abbey, The A List, Dracula, Call the Midwife. All British. None sci-fi. The similarity score is real, but the content match is wrong.
Squid Game has the same problem in a different shape. Its tags drag it into the Korean-international-thriller cluster, which captures some of the right vibe but misses the specific survival-game conceit.
Stranger Things is the one that works cleanly. The tags — TV Horror, TV Mysteries, TV Sci-Fi & Fantasy — are specific enough that the neighborhood fills with other sci-fi-horror shows. Nightflyers, Helix, Chilling Adventures of Sabrina, Manifest, The 4400. That’s a defensible top-5.
A Stranger Things animation
Sixteen frames stepping through the type penalty. The movie count drops to zero almost immediately because the query is a TV Show and any small penalty pushes movies out. The top-3 shuffle a little but the neighborhood is already TV-Show-dominant even at weight zero.
The animation is useful less for demonstrating a problem to solve than for showing how sensitive the ranking is to a small penalty weight. For a curator who wanted to nudge the neighborhood, 0.1 to 0.2 is a reasonable range.
The similarity matrix
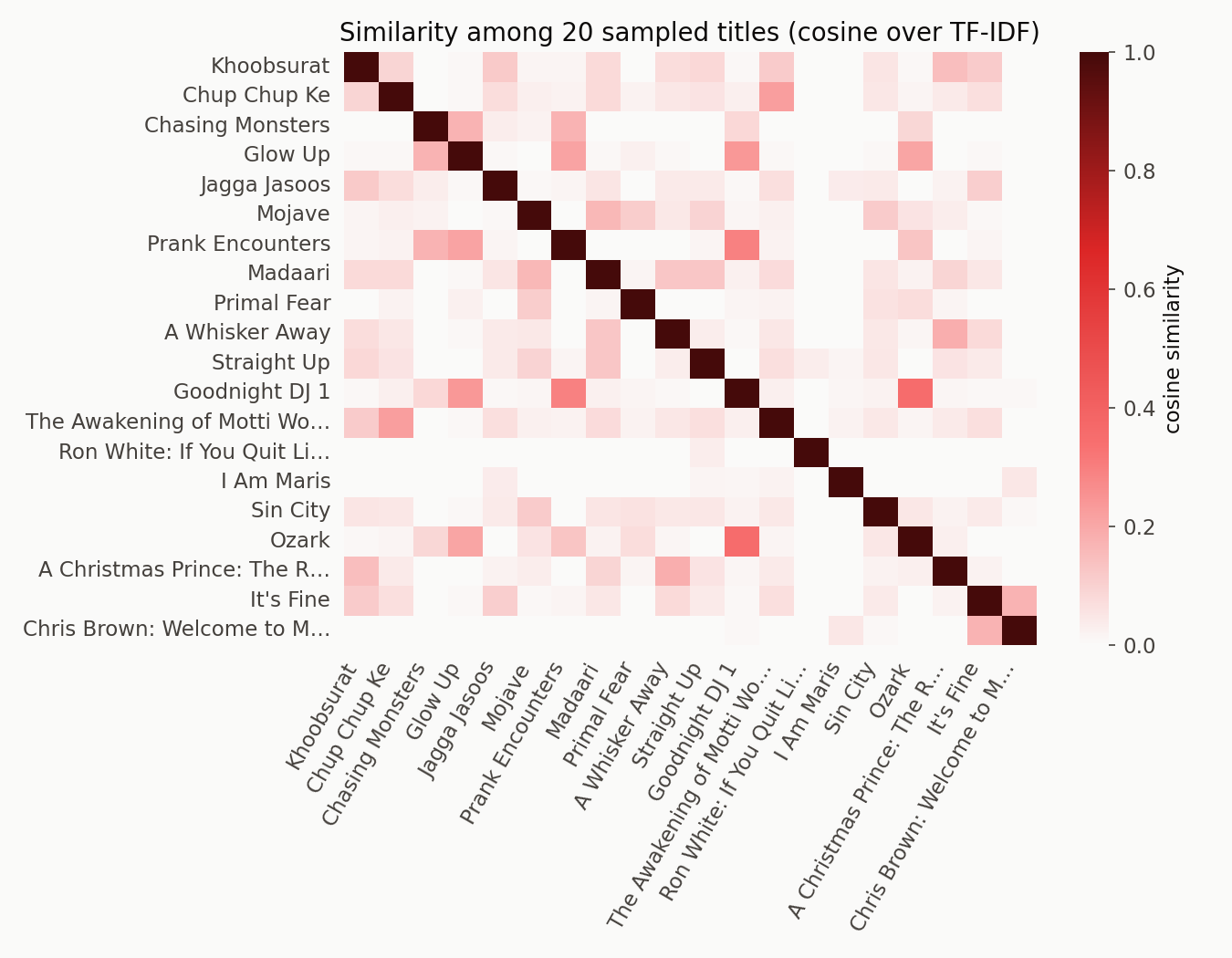
The off-diagonal is mostly near-zero with a few bright spots where two titles share vocabulary or tags. That sparsity is the shape you want in a content recommender — most titles are unrelated, and the ones that are related stand out cleanly.
What would make this better
A TF-IDF + BM25 comparison — BM25 handles long-tail common tags more gracefully. A multi-tag embedding approach that separates content similarity from tag membership would mitigate the genre-tag shadowing directly. And a behavioral layer — co-watch patterns or rating correlations — is what a real Netflix recommender actually runs. Description text alone is never going to beat “people who watched Stranger Things also watched”.
For a 30-line text recommender, what’s here is already doing the work. That’s the honest takeaway.
Reproducibility note
Source, notebook, and outputs are in github.com/ndjstn/netflix-content-recommender. The dataset is the netflix_titles.csv from Shivam Bansal’s Kaggle dataset (Bansal, n.d.).