The One Human a 99.84 Percent AI Text Detector Got Wrong
A bigram TF-IDF linear SVM on the Akbulut AI and Human text corpus reaches 0.9984 accuracy on a 1,214-row holdout. Exactly two predictions are wrong. One of them is a human writer labeled as AI. That cell is the whole story.
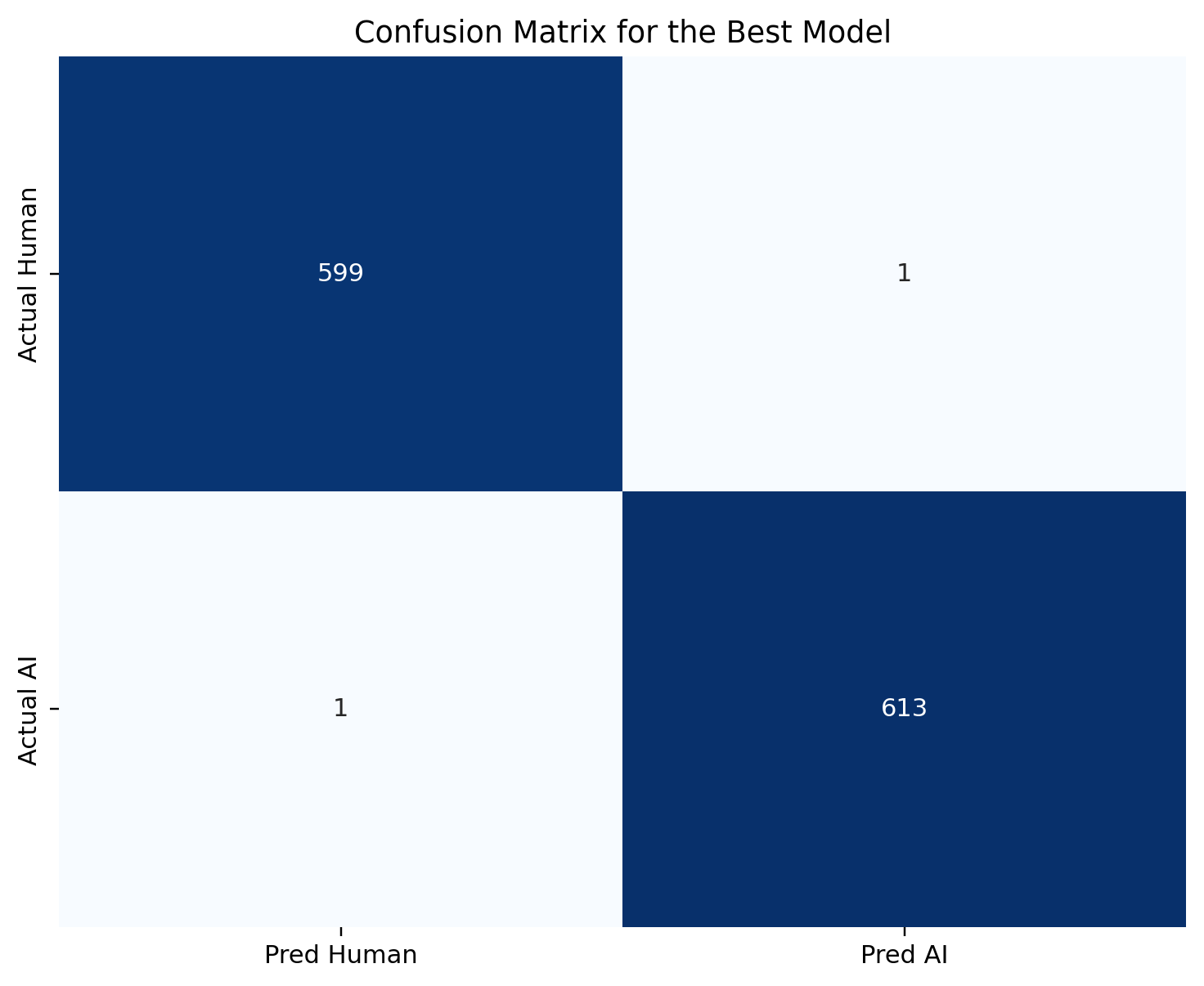
A bigram TF-IDF linear SVM, trained on Akbulut’s AI and Human Text Kaggle corpus, reaches 0.9984 accuracy and a ROC-AUC of 0.9999728 on a held-out 1,214-row test set. That is as close to ceiling as a 1,214-row evaluation can resolve.
Exactly two predictions are wrong. One AI document is labeled as human — a missed detection that a human reviewer can recover from. One human document is labeled as AI. That second error is a real person whose writing the classifier misidentified, and it is the part of the confusion matrix that governs every deployment decision from here.
The rest of this post is the argument that a detector this accurate still cannot stand as evidence of authorship.
The dataset
The corpus is Akbulut’s AI and Human Text Dataset, distributed on Kaggle under a CC BY 4.0 license. After dropping rows with missing text and removing exact duplicates, the working sample holds 6,069 documents: 3,069 labeled AI, 3,000 labeled human.
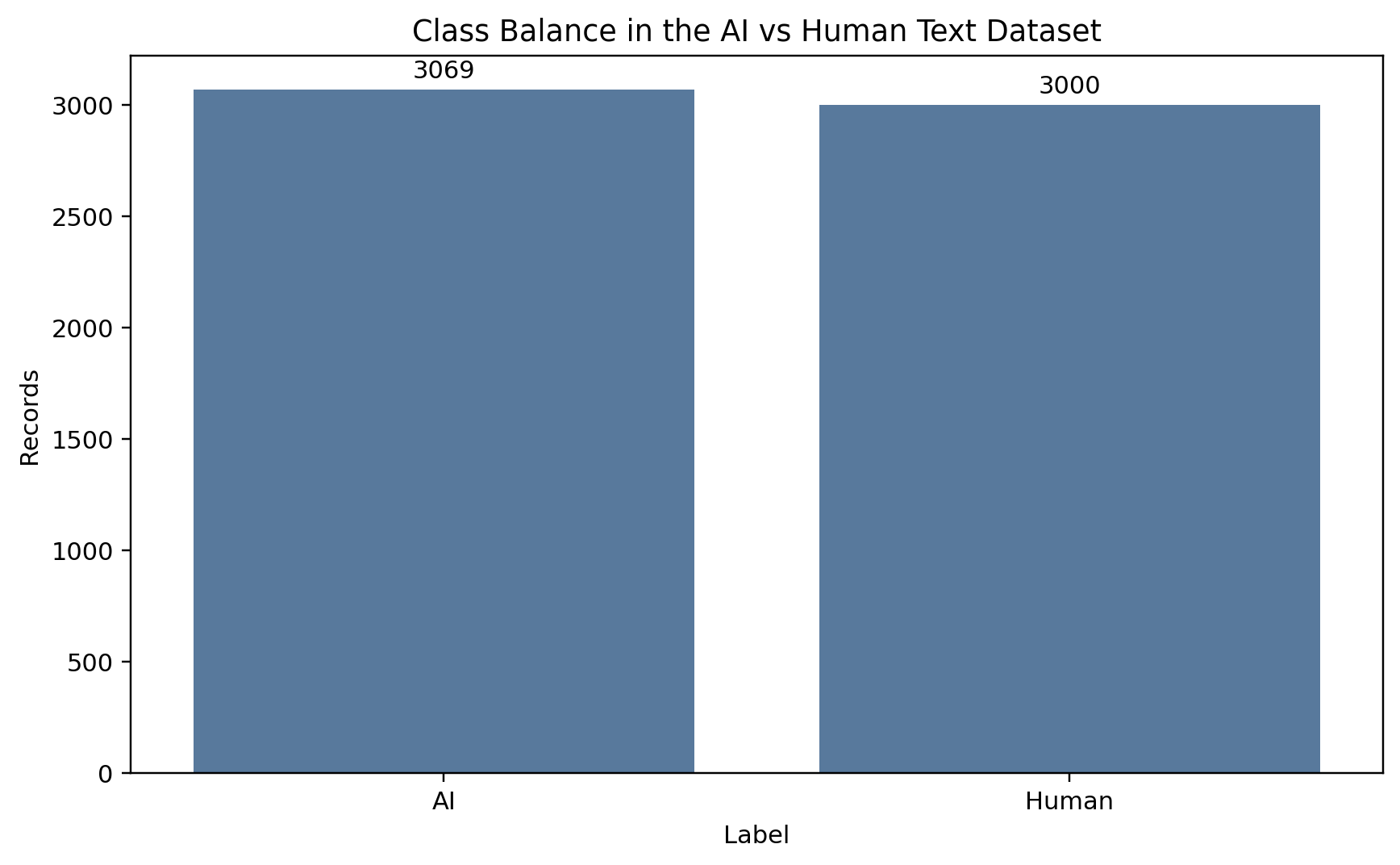
Class share is 50.57 percent AI against 49.43 percent human. A majority-class baseline floors at 50.58 percent accuracy, which rules out label skew as an explanation for any later gain.
Near-balance matters because it means every point of accuracy a trained model earns is earned on real signal, not on label skew. The baseline can’t fake performance here.
The working split is stratified 80/20 at a fixed random seed, producing 4,855 training documents and a 1,214-row test set. AI is the positive class throughout, so a false positive is a human document labeled as AI and a false negative is an AI document that went undetected. That naming matters for the rest of the post.
The length gap is six to one
Before any model runs, there is one structural fact about this corpus that every result has to be read against. AI documents in Akbulut’s corpus are short. Human documents are long.
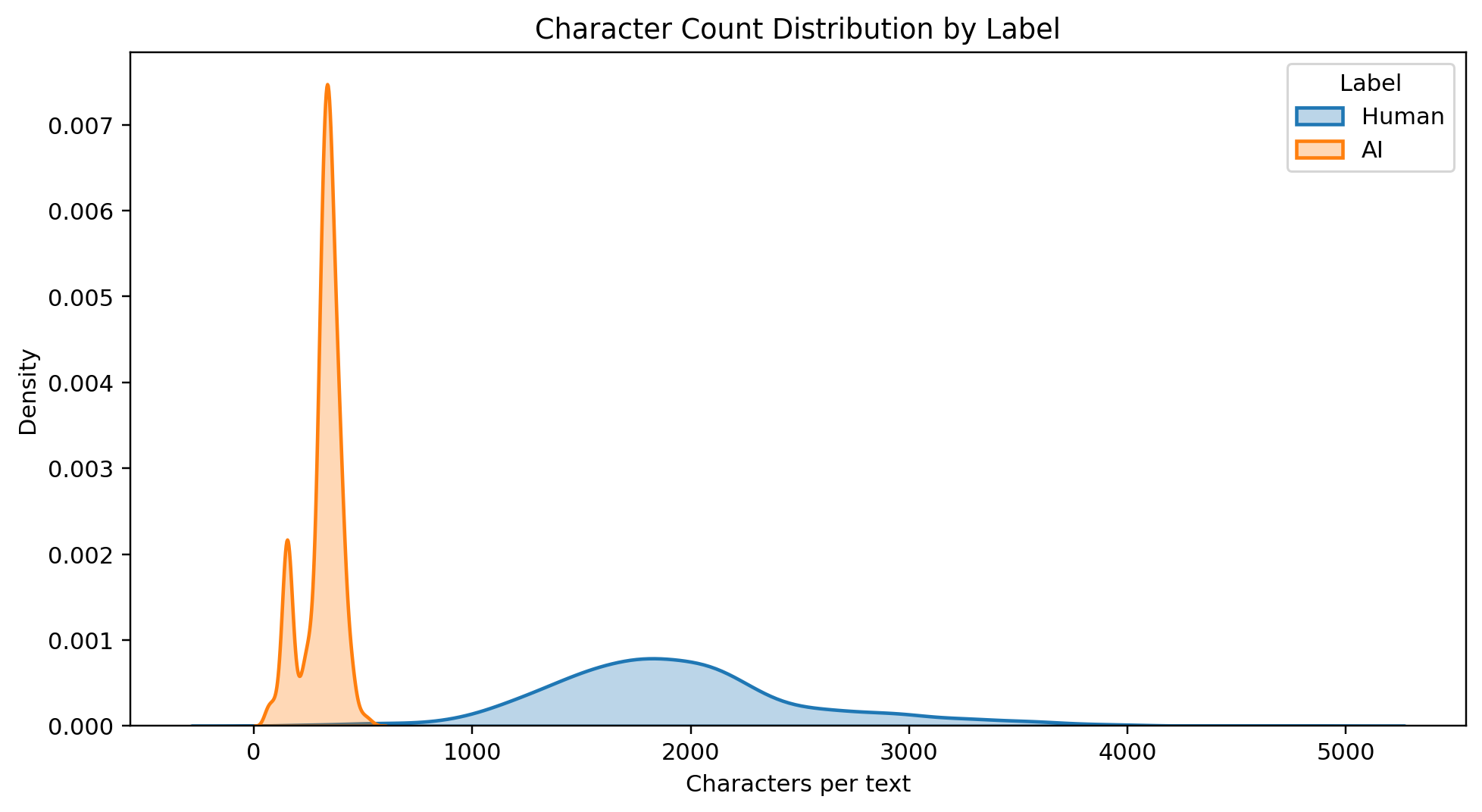
The overall histogram. Median character count is 455; the mean is about 1,118, dragged up by a long right tail of long human documents.
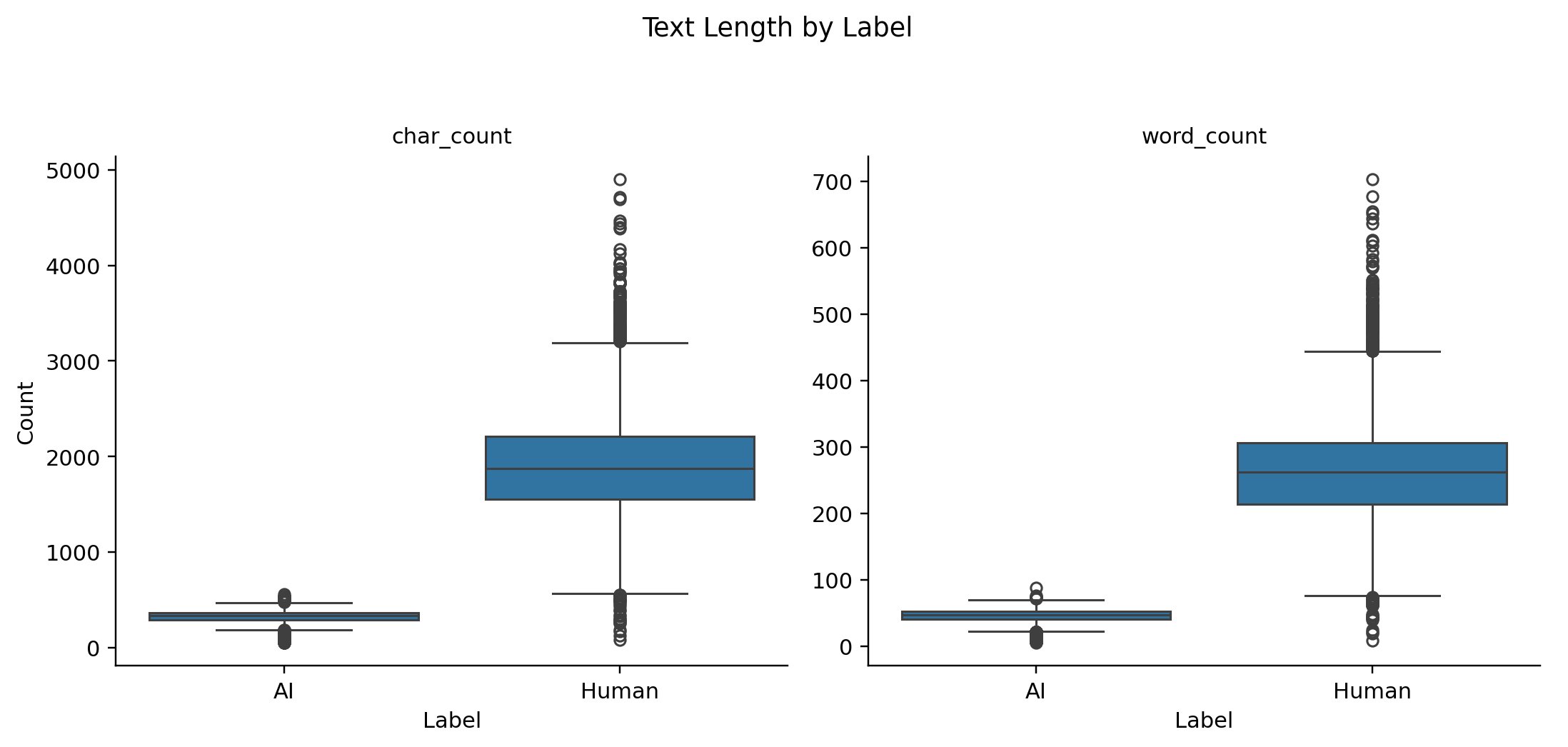
Per-class: AI documents average 313 characters and 44 words. Human documents average 1,942 characters and 271 words. Roughly a six-to-one gap in character count.
That gap is not cosmetic. A classifier trained on TF-IDF features computed from documents of very different lengths sees feature distributions that are partially confounded with document length. A linear model given this corpus could be learning “AI text is short and uses certain terms” rather than anything deeper about generation patterns.
Separating length from style would need a length-matched evaluation, which this dataset does not support without discarding most of the human samples. The confound is known, it is not fixable on this corpus alone, and the headline accuracy number should be read with that awareness from the start.
A three-step ladder
I ran three models in sequence, each layering on top of the last.
| Model | Features | Accuracy | AI F1 | ROC-AUC |
|---|---|---|---|---|
| Majority baseline | label prior only | 0.5058 | 0.6718 | 0.5000 |
| Unigram TF-IDF logistic regression | unigrams | 0.9835 | 0.9838 | 0.9984 |
| Bigram TF-IDF linear SVM | unigrams + bigrams | 0.9984 | 0.9984 | 0.9999728 |
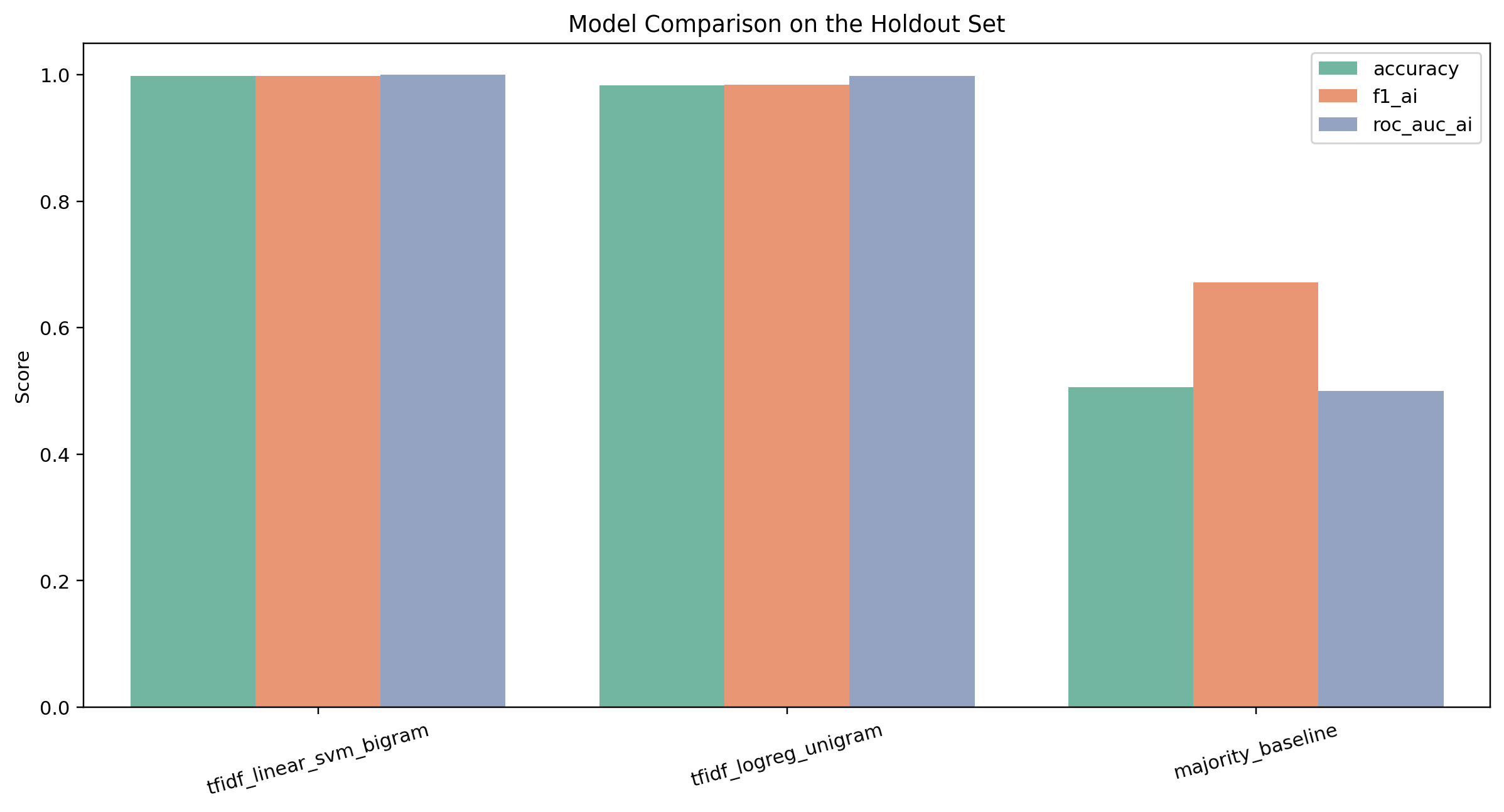
The shape of the ladder matters. Most of the performance comes from unigrams. Adding bigrams closes most of the remaining gap but is a small refinement, not a different kind of model.
The largest lift in the entire ladder is the first one. Going from the majority baseline to a unigram TF-IDF logistic regression adds about 48 points of accuracy. Adding bigrams on top of the unigram model adds roughly 1.5 points. That shape tells you that the class signal in this corpus is largely lexical at the word level — simple weighted counts of terms are almost enough to separate AI from human. Bigrams refine the decision boundary the unigram model already drew. They do not reveal a categorically different kind of signal.
The bigram linear SVM is the best model in the project. It reaches 0.9984 accuracy with AI precision, recall, and F1 all rounding to 0.9984, and a ROC-AUC of 0.9999728 on the 1,214-row holdout.
Two errors and a difference that matters
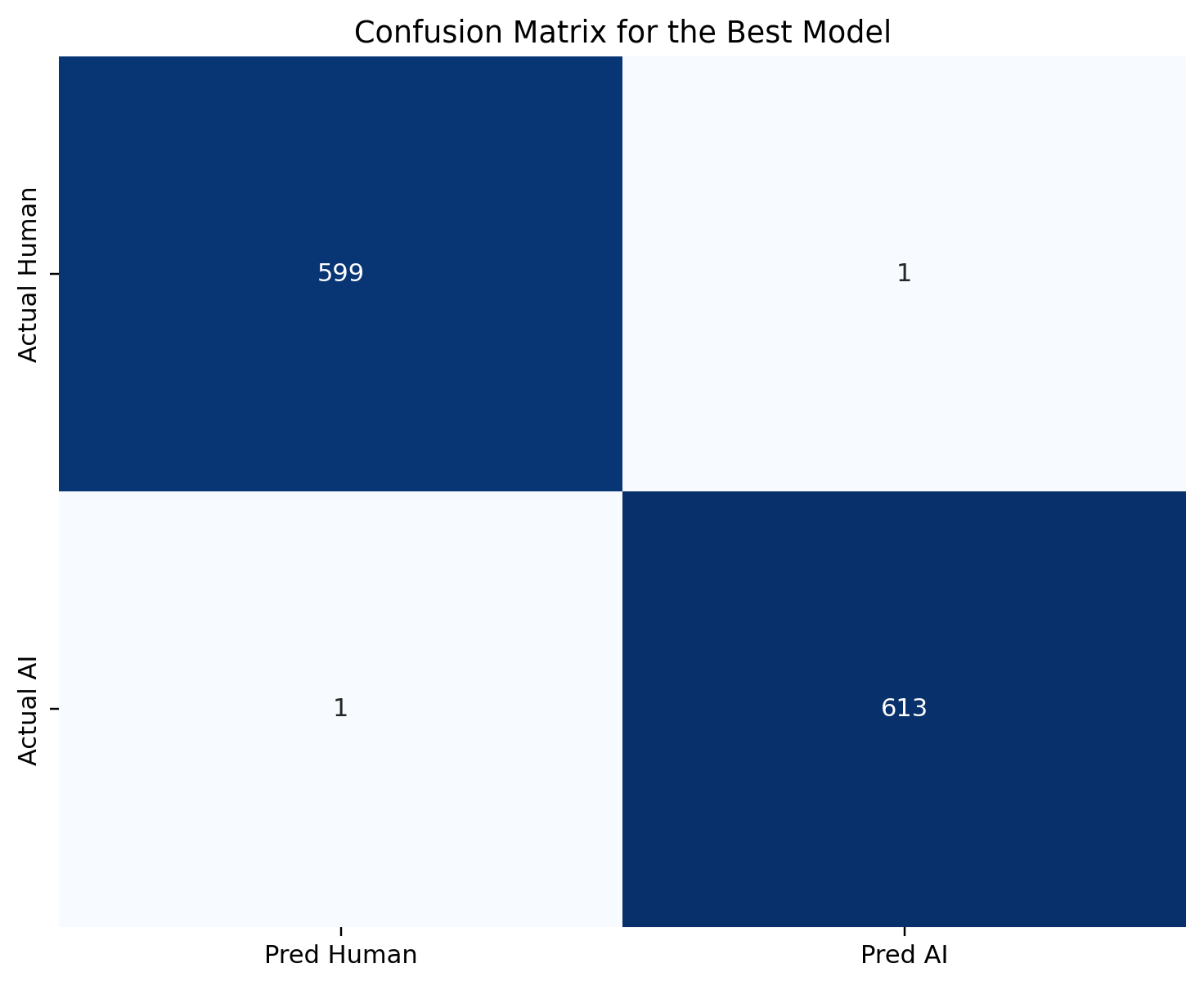
1,212 correct predictions. One AI document labeled as human. One human document labeled as AI. Those two off-diagonal cells are the whole deployment discussion.
Let me name the errors concretely. One AI document out of 614 in the test set was labeled as human — a false-negative rate of 0.16 percent. One human document out of 600 was labeled as AI — a false-positive rate of 0.17 percent. At these counts, the confidence intervals around both rates are wide. An 0.17 percent rate on 600 documents means roughly one observation; a resample could plausibly produce zero or two.
Statistically, those two errors look symmetric. Operationally, they are not.
The false negative is recoverable. An AI document that slipped through is a detection miss; it does not, on its own, do harm to anyone. A human reviewer reading the same document can correct the label downstream. The cost of that error is bounded at the time of detection.
The false positive is categorically different. A human writer’s document was labeled as AI. If this classifier were deployed as part of an academic-integrity workflow without human review of every flag, the consequences of that error are real and potentially severe: grade penalties, misconduct proceedings, in some institutions suspension or expulsion. The person whose document was misidentified is being asked to prove a negative under conditions where a classifier score is being presented as evidence.
An 0.17 percent false-positive rate sounds small. At a university with 10,000 students submitting multiple assignments a semester, it produces many wrongful flags per year. That arithmetic is the reason detector metrics that look perfect on paper can still create structural harm at scale.
What the coefficients are actually picking up
Top-term analysis on the logistic regression makes the vocabulary signal legible. Human-side terms cluster on first-person markers and conversational constructions. AI-side terms cluster on abstract hedging and topic-specific noun phrases.
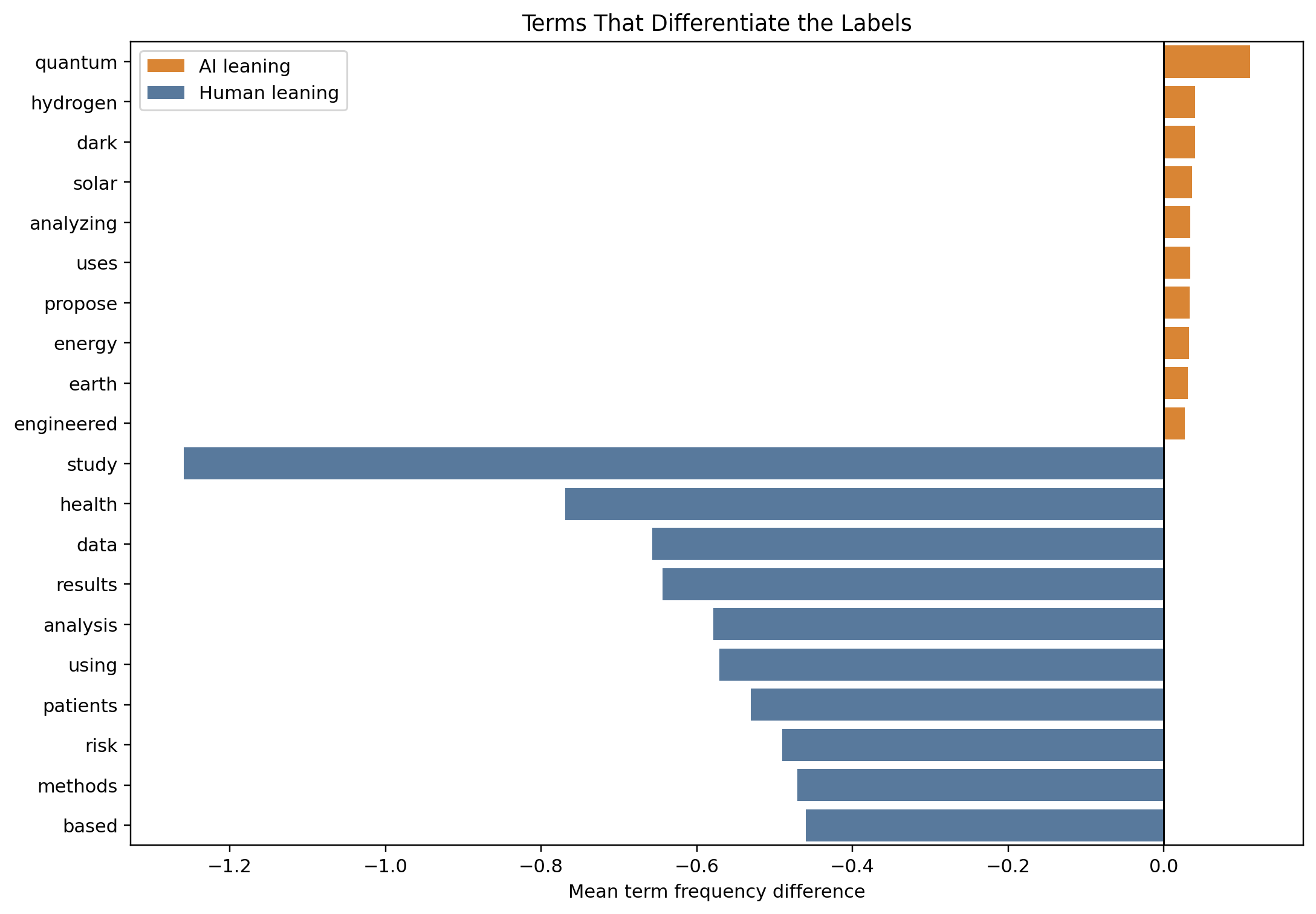
The top discriminative tokens are concrete vocabulary items, not syntactic scaffolding. The vocabulary difference is real. What is less clear is how much of it is intrinsic to generation and how much is an artifact of the specific prompts this corpus was drawn from.
That distinction matters. Some of the heaviest AI-associated terms may be there because AI documents in this corpus happen to be drawn from a narrow topic distribution rather than because machine-generated text has an intrinsic preference for those terms. Without prompt metadata or a generator identifier, there is no way to audit whether the learned features reflect generation style or corpus topic structure.
What it is not
The result is genuinely useful as a research artifact. It demonstrates that Akbulut’s corpus carries strong, learnable lexical signal. It demonstrates that bigram features add measurable value over unigrams. It produces a small, interpretable confusion matrix that the ethics discussion can hold on to.
What the result is not is a deployed detection system.

Four structural limits. Any one of them could change the error rate on a different corpus, a different generator, or a different writer population.
Four limits shape what this number can and cannot support. The length confound means the classifier may be partly a length detector wearing an AI-detection label. The absence of metadata means I cannot audit the classifier for topic-specific shortcuts or characterize the human writing population behind the corpus. The static-snapshot problem is that AI output drifts as training data, RLHF, and model scale evolve; a detector trained on this corpus is fit to one slice of that distribution and may not transfer. The adversarial gap is that no document in this evaluation was deliberately modified to evade detection, and real-world evasion is easy enough that any deployment with stakes has to assume it is happening.
The literature has been saying this for years. Sadasivan and colleagues (2023) argued theoretically that statistical detectors lose reliability as generator quality improves and the human and AI text distributions begin to overlap. Crothers and colleagues (2023) documented that no single detection method dominates across contexts; a detector that works on one corpus, one generator, or one prompt style does not automatically transfer. Uchendu and colleagues (2020) showed that neural-text attribution systems struggle to generalize across domains, which is directly relevant here because the features that distinguish AI from human text in one corpus may be corpus-specific artifacts. The broader pattern: benchmark accuracy is not evidence of deployment-ready capability.
Recommendation
The narrow and specific recommendation: this classifier must not be used as evidence in academic-misconduct proceedings. The number 0.9984 is not a forensic standard of proof.
A defensible use for a detector like this is as a triage signal inside a human review workflow. A score above a threshold should trigger a closer look by a qualified reviewer, and the reviewer should treat the score as one input alongside submission history, source context, and other available information. Borderline cases should escalate rather than resolve automatically. Every prediction the model makes in a live setting should be logged with input text, model version, score, threshold, and reviewer outcome so drift and error can be audited afterward.
The point of that discipline is simple. The single human document this classifier misidentified, on the cleanest corpus it was ever going to see, is a concrete reminder that automation without review is how error becomes harm.
Reproducibility note
The full pipeline — loading, deduplication, stratified splitting, TF-IDF vectorization, three model fits, coefficient inspection, and every figure in this post — runs end-to-end from the Kaggle CSV. Source code, the notebook, and the figure outputs live in the public repository at github.com/ndjstn/ai-human-text-detection. The dataset is Akbulut’s AI and Human Text Dataset on Kaggle, distributed under CC BY 4.0.