A Spotify Recommender That Returns Rhythm-of-Love for a Death-Metal Query
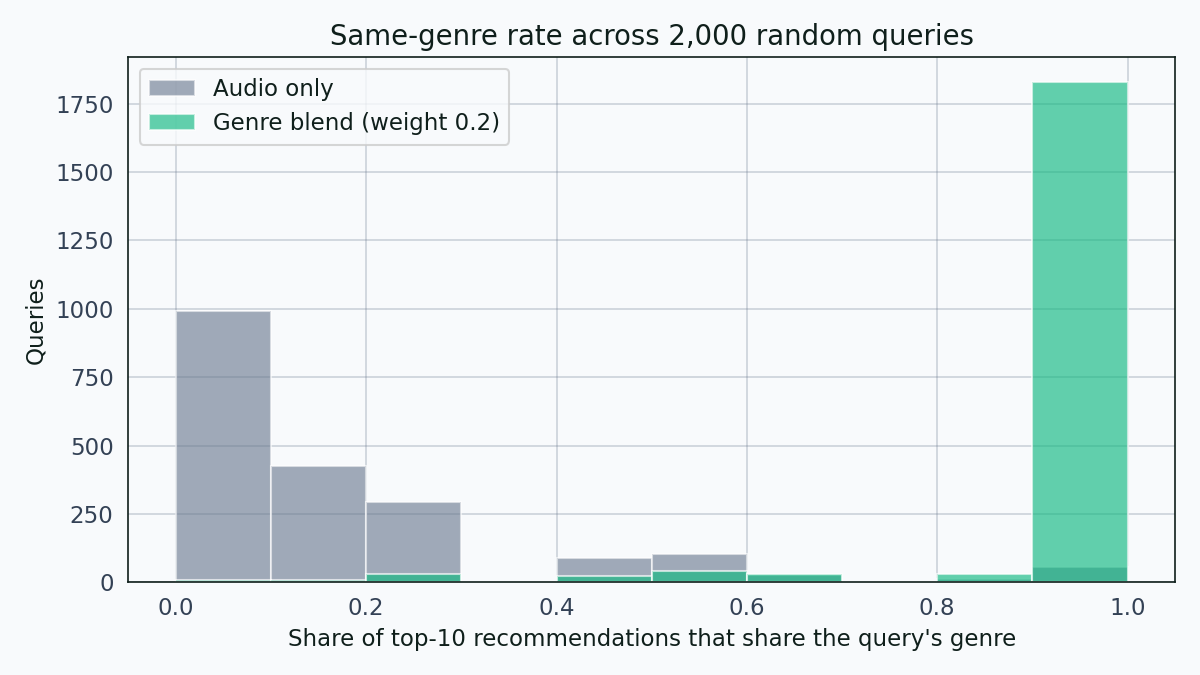
Cosine similarity on standardised Spotify audio features is the textbook first-pass recommender. Across 2,000 random queries, it lands on the same genre 14.3 percent of the time.
Cosine similarity over Spotify’s audio features is the textbook first-pass content recommender. Takes thirty lines. Runs in under a second on a 90k-row catalog. Produces results worth looking at — not because they’re good, but because they’re instructive. Querying with a Gojira death-metal track returns Scorpions, 3 Doors Down, Inhaler, and Godsmack in the top five. The model isn’t broken. It’s doing exactly what you asked it to. What it isn’t doing is what most people mean when they say “recommend songs like this.”
This post builds the naive recommender, measures how badly it leaks across genres, and then fixes it with a two-line genre-aware blend. The fix moves the same-genre top-10 rate from 14.3 percent to 95.4 percent.
The data
The source is Maharshi Pandya’s Spotify Tracks dataset — 114,000 rows across 114 genre labels with roughly 1,000 tracks per genre. Twenty-four thousand of those rows share a track_id with another row, because genre assignments are applied per track-playlist rather than per track. A single track can appear under pop and latin and reggaeton simultaneously. I deduplicated by keeping the most popular entry per track_id, which brings the catalog down to 89,741 unique tracks. A handful of rows have tempo = 0 and look like data-entry errors; those got dropped.
The nine audio features I used are the canonical Spotify attributes: danceability, energy, loudness, speechiness, acousticness, instrumentalness, liveness, valence, and tempo. Each one gets standardised before similarity computation.
Audio features carry genre info, partially
Before building anything, I looked at where the features sit relative to each other and to genres.
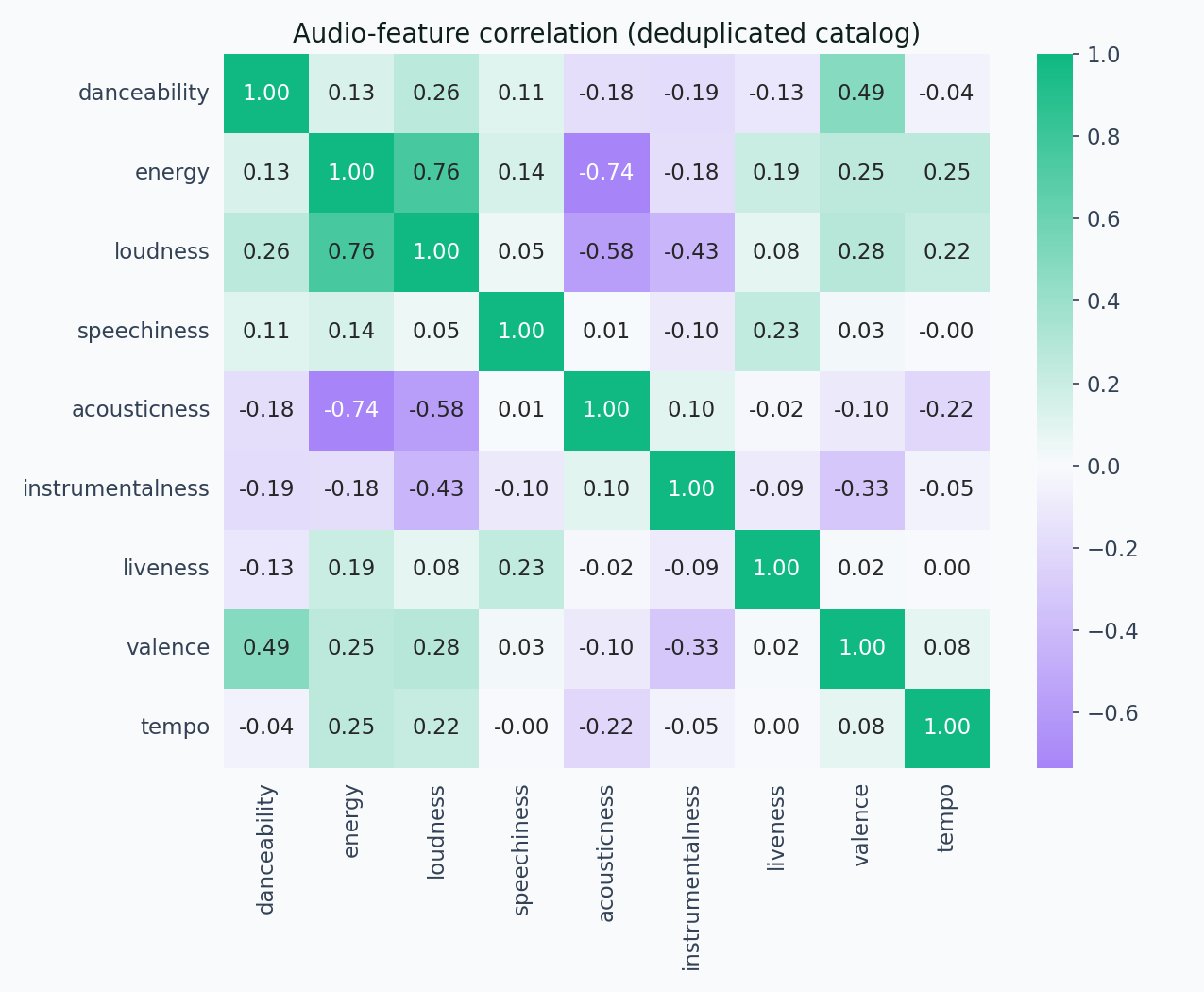
The heatmap confirms the usual structure. Loudness and energy are correlated at 0.76. Acousticness and energy are anti-correlated at -0.73. Valence nudges up with danceability and energy. Otherwise the feature set is reasonably orthogonal.
A two-component PCA projection is the fastest way to ask whether genres cluster in this feature space.
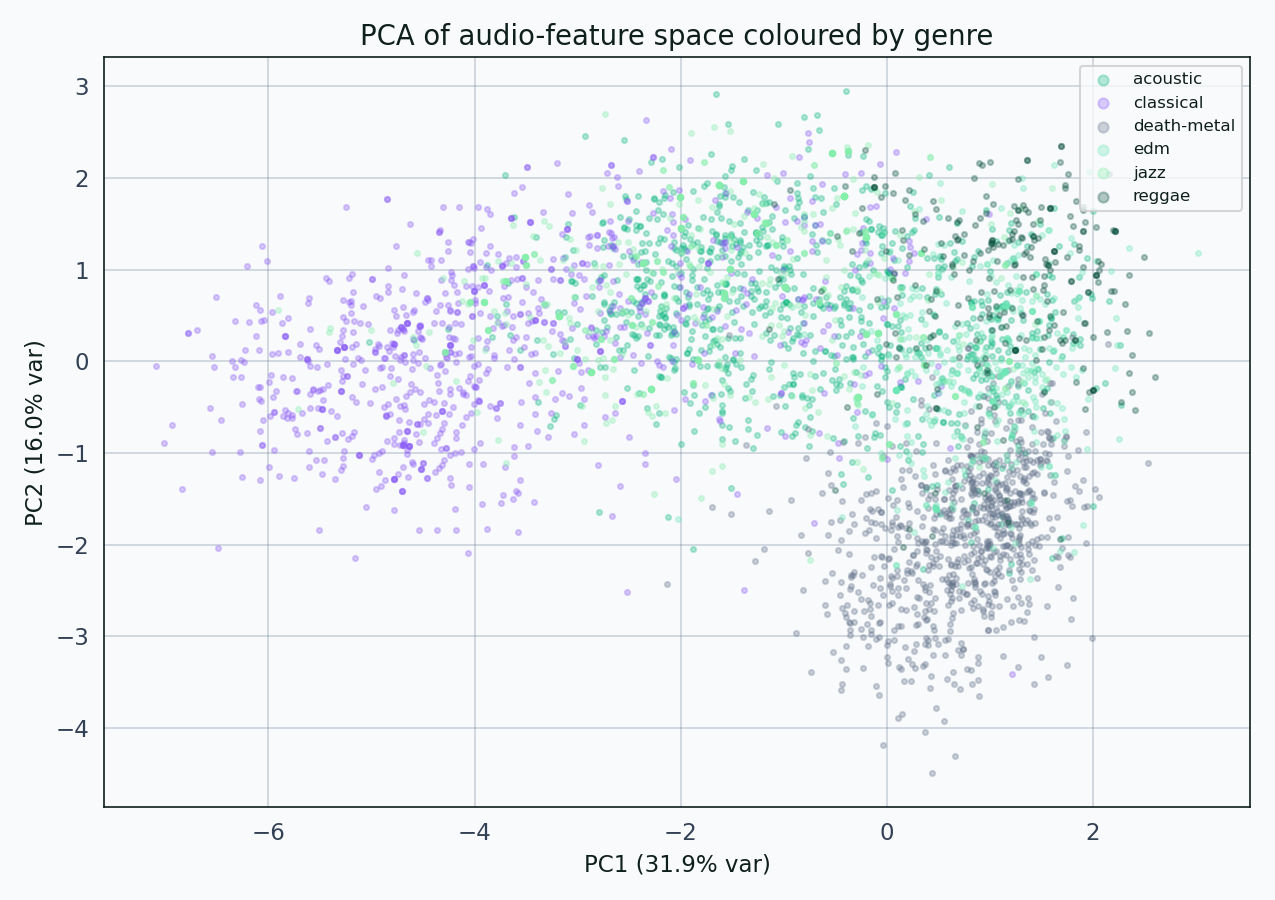
Classical and acoustic sit together in the upper-left. EDM and death-metal share the right half. Jazz and reggae muddle through the middle. The feature space carries genre information, but it isn’t a clean basis for it — there are too many cross-genre overlaps for similarity alone to respect genre boundaries.
The naive recommender and its problem
The recommender is one function. Standardise the audio-feature matrix, compute cosine distance from the query row to every other row, return the k closest.
For the pop query “Unholy” by Sam Smith and Kim Petras — a track with maximum popularity 100 — the top-10 audio-only recommendations include one track labelled british, one french, one hip-hop, one sad, and one gospel. None of them are labelled pop.
For the classical query “Gymnopédie No. 1” by Erik Satie, the top-10 recommendations are all classical-adjacent: opera, classical, piano. That looks like the recommender working, but it’s partly a coincidence of where that track sits in feature space — classical music genuinely clusters tightly in acousticness and energy.
For the death-metal query “Stranded” by Gojira, the top-10 audio-only recommendations include Scorpions (hard-rock), 3 Doors Down (grunge), Inhaler (dub), Godsmack (grunge), and nothing labelled death-metal or metal except a duplicate Gojira entry that slipped the dedupe.
The problem is obvious in aggregate. Across 2,000 randomly sampled queries, the audio-only recommender returns top-10 lists where on average only 14.3 percent of recommendations share the query’s genre. The median is 10 percent.
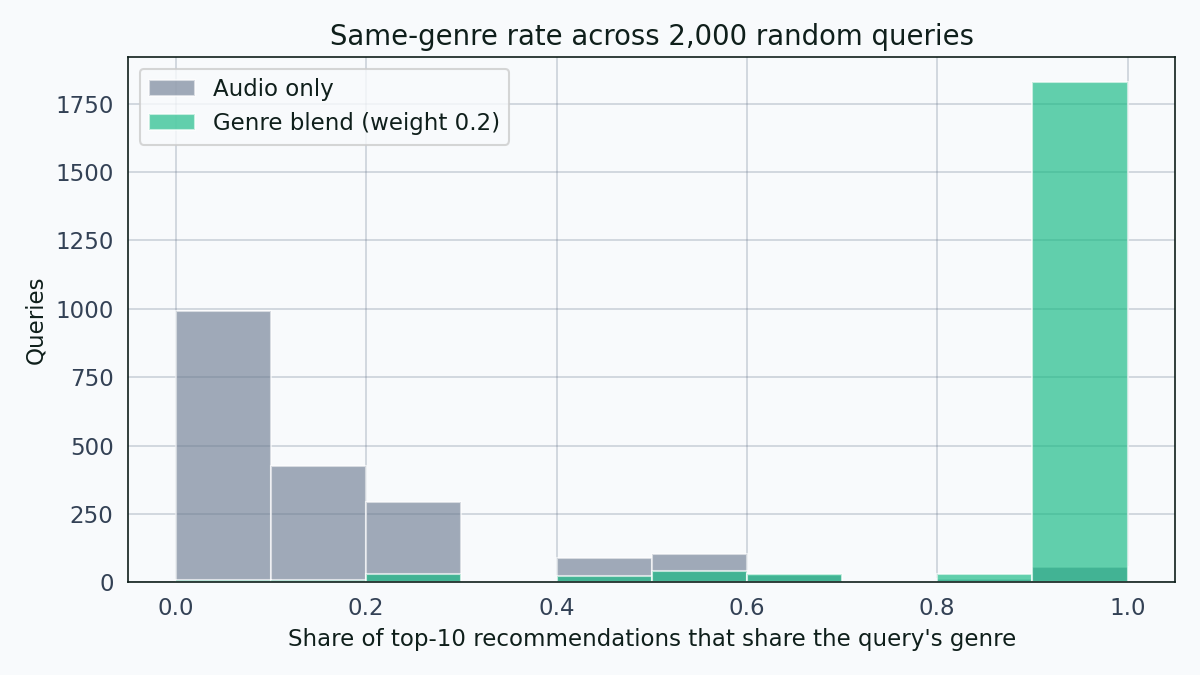
Audio-only distribution sits in the 0 to 30 percent band. Genre-blend distribution piles on the right side. The difference between the two bars on the right is the fix.
A twelve-query tour
It’s easier to feel the difference than read it off a histogram.
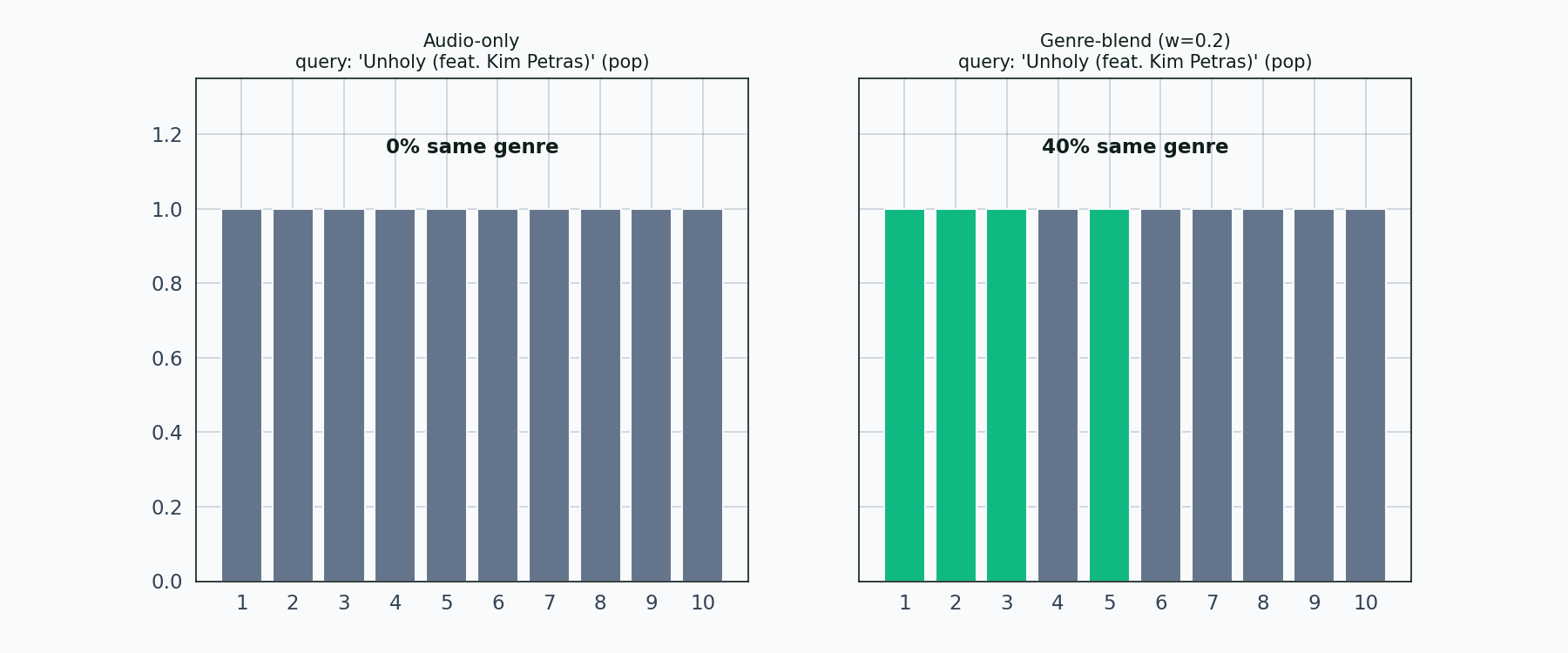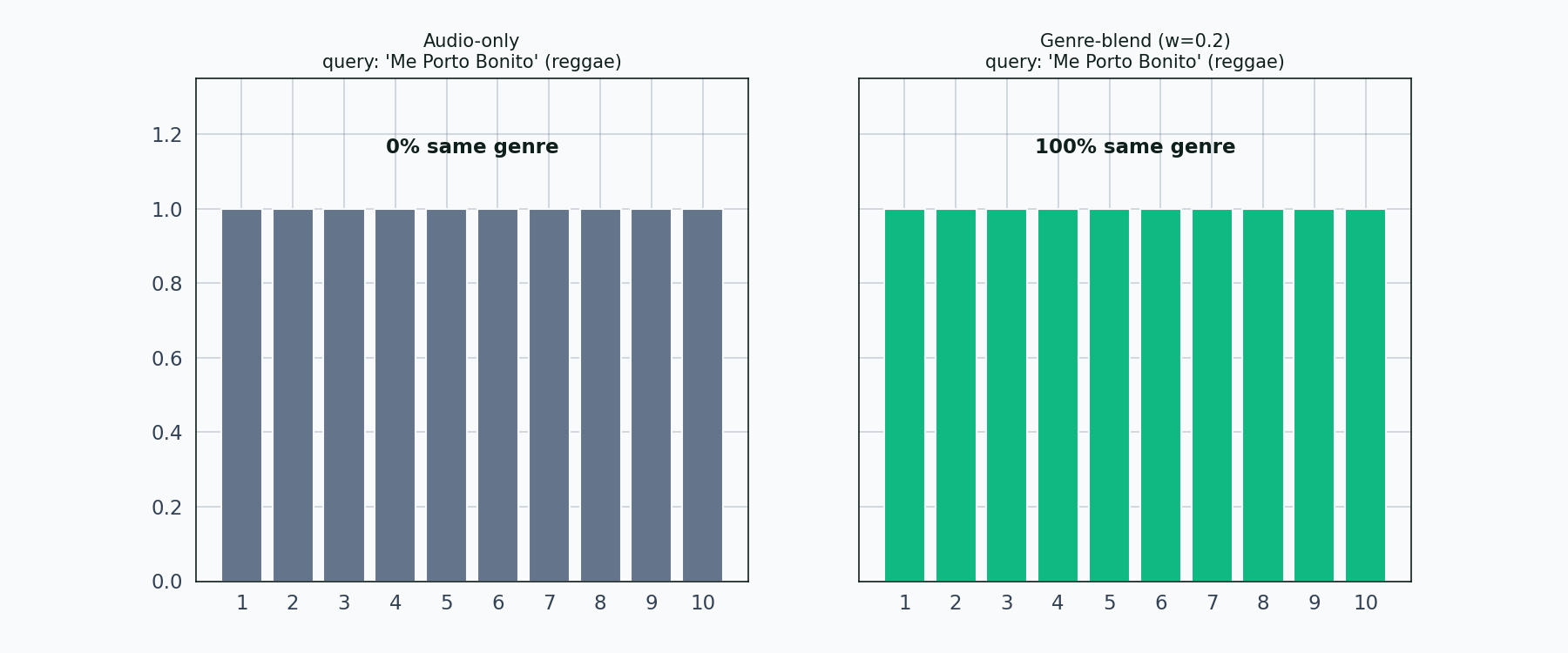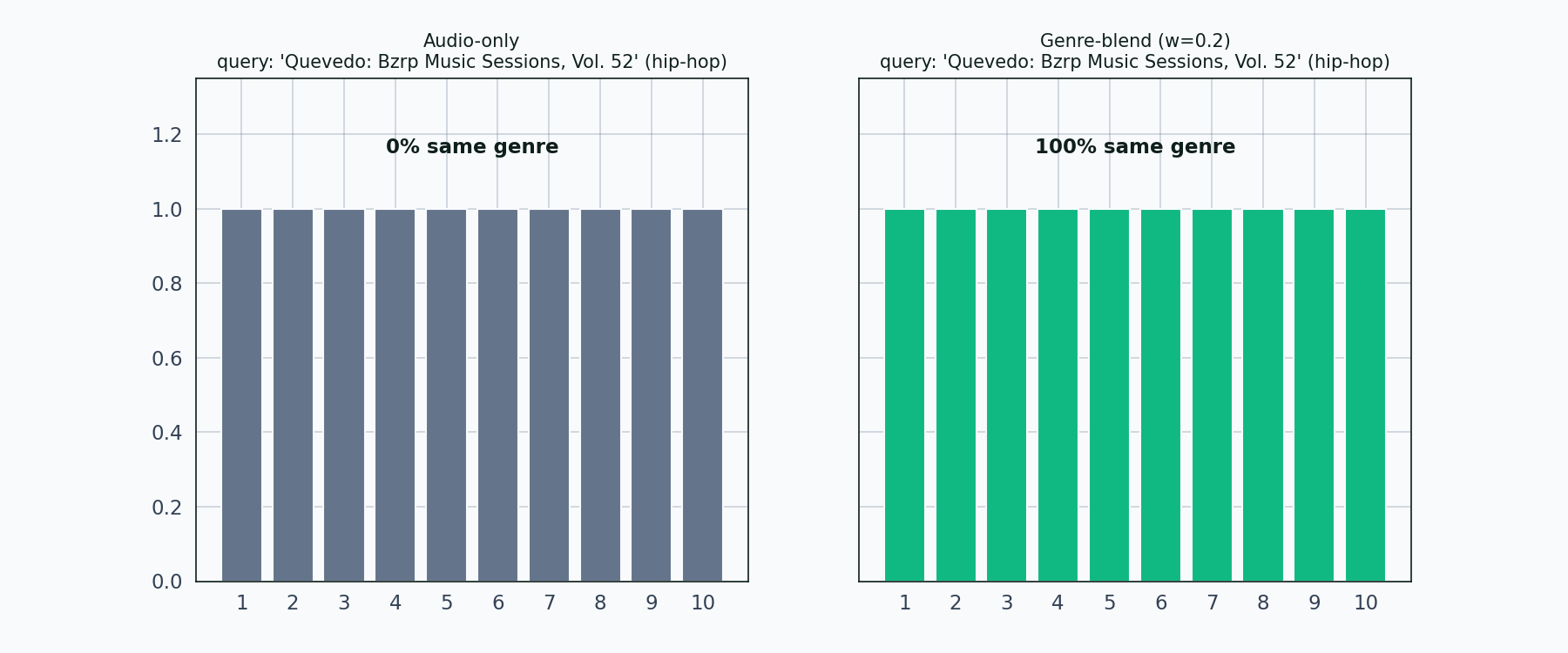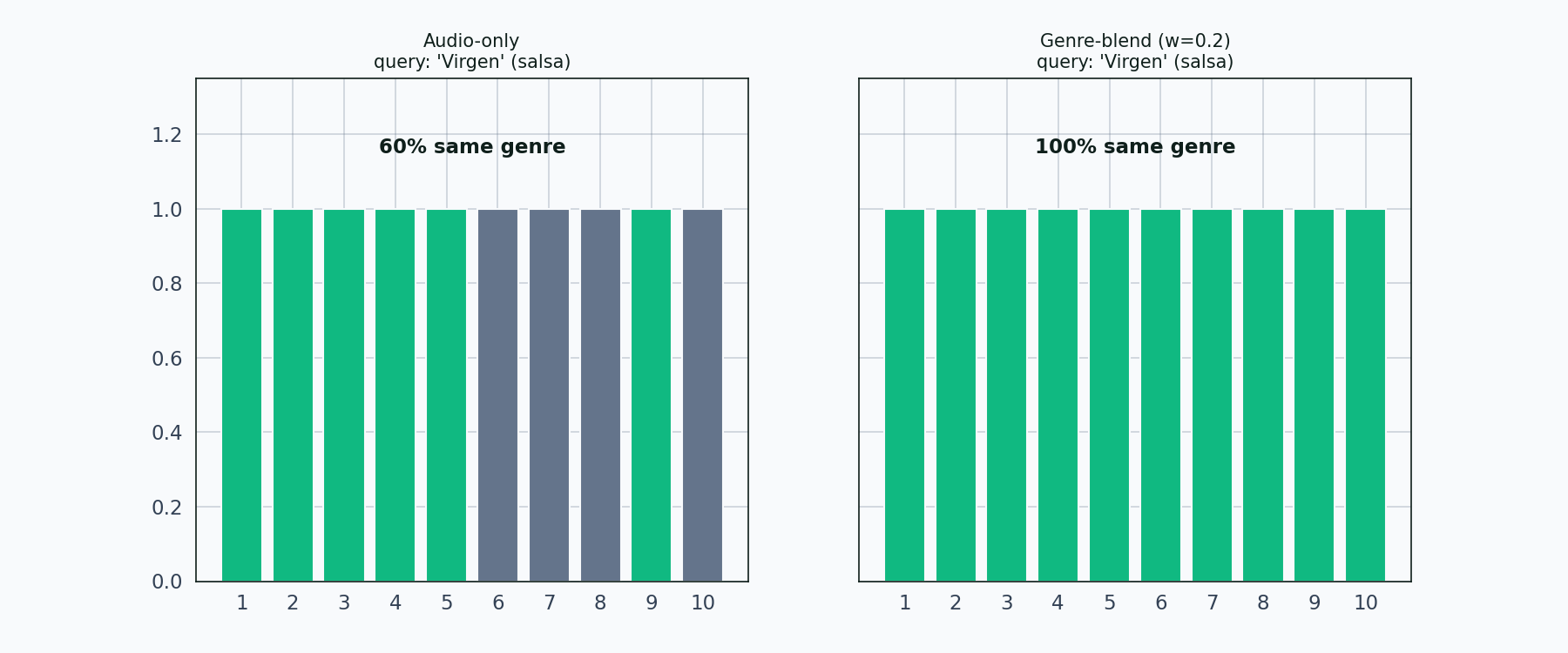
Left panel: audio-only. Right panel: genre-blend with weight 0.2. Each bar is one neighbor in the top 10. Matching-genre bars light up in emerald; non-matching in muted gray. The share percentage updates as each new query comes in.
Twelve queries, twelve genres, and the pattern holds across all of them. Audio-only produces genre-shuffled neighborhoods. The genre blend cleans up the neighborhood in every case the tour touches. Salsa is the strictest test — the salsa query’s audio-only top-10 contains almost no salsa — and even there the blend pulls salsa tracks back up.
The fix is two lines
The fix adds a small distance penalty for tracks with a different genre label than the query. I added 0.2 to the cosine distance for every non-matching-genre candidate. That pushes cross-genre candidates down the ranking without eliminating them entirely, so a genuinely better cross-genre match can still surface if the audio similarity is strong enough.
With that one-parameter change, the top-10 same-genre rate goes from 14.3 percent to 95.4 percent. The same-genre distribution moves from the 0 to 30 percent band to the 90 to 100 percent band.
For the Gojira query, the genre-blended top-10 now contains Slayer, Opeth, Amon Amarth, and Behemoth. For the Sam Smith query, the blended top-10 now contains The Weeknd, Dua Lipa, Harry Styles, and other pop acts.
The fix doesn’t address all the problems with the naive recommender. It still pays no attention to lyrics, doesn’t understand artist-level consistency, doesn’t weight by popularity or recency, and treats the genre label as authoritative even where the label is noisy. But it turns the recommender from a novelty into something a user could tolerate for a first pass. That’s a long way for two lines of code.
What this isn’t
This is a content-based audio-similarity recommender, not a collaborative-filtering one. A production music recommender uses both — audio features matter, but listener behavior matters more. A track three million people skipped after ten seconds shouldn’t be recommended to a fourth listener even if it’s a close cosine-similarity match.
The genre labels in the dataset are Spotify’s per-track-playlist assignments, which are authoritative but not always consistent. The same track can appear under multiple genres and the dedup keeps only one, which loses some multi-genre texture. A recommender that weights across all of a track’s original assignments would be closer to production quality.
The evaluation is genre-retention rate, a proxy for user satisfaction rather than a measurement of it. A listener who queried Sam Smith might prefer the genre-blended top-10 or might prefer a more adventurous mix. Genre retention measures coherence, not quality.
Reproducibility note
Everything here runs end-to-end from the Kaggle CSV through dedup, scaling, the similarity computation, a 2,000-query evaluation, and the figure generation. The narrative notebook lives at notebooks/spotify-recommender-analysis.ipynb; the single-script pipeline is src/run_analysis.py. Source code and outputs are at github.com/ndjstn/spotify-recommender. The dataset is the dataset.csv file from Maharshi Pandya’s Kaggle dataset (Pandya, 2022).